Incremental Learning In Online Scenario
Purdue University researchers recently developed a novel method that makes class incremental learning feasible in the strict online learning scenario which are additionally bounded by run-time and capability of lifelong learning with limited data compared to offline learning. Modern deep learning approaches have achieved great success in many vision applications by training a model using all available task-specific data together. However, when new classes occur in sequential order and we continuously update the model using only new class data, these methods suffer from catastrophic forgetting, where the model quickly forget already learned knowledge due to the lack of old data.
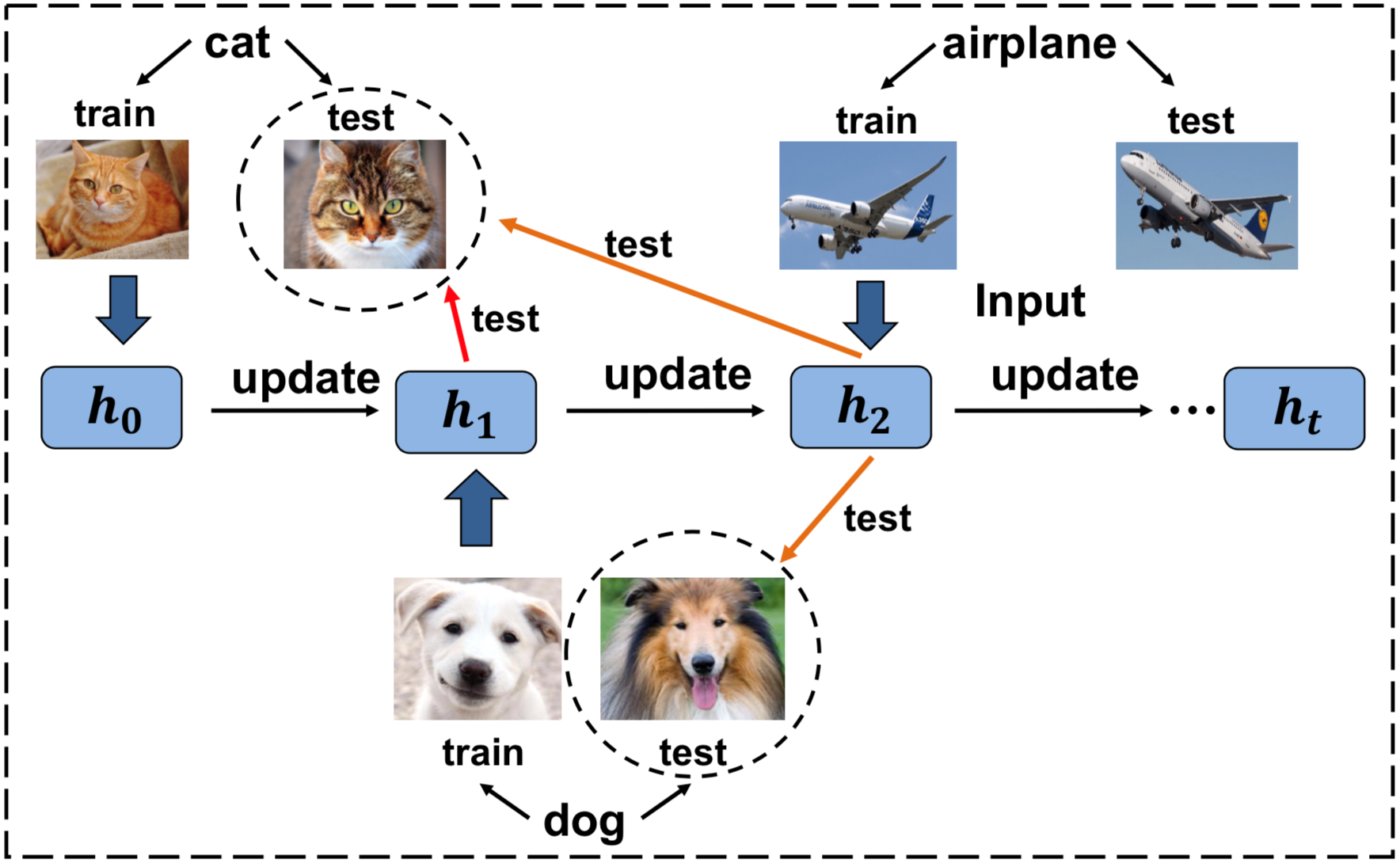
“Current state-of-the-art class incremental learning methods assume the ideal case that all data in current incremental learning step is available, so they require a long time offline training with many epochs (e.g., 100-120 epochs) for each step.” said Jiangpeng He, a PhD student of Prof. Fengqing Zhu, assistant professor of ECE. “However, it is difficult to apply their algorithms in the non-ideal case that within each incremental step, the new data becomes available sequentially, which is closely related to the challenging online learning scenario. Our research answers the question: Can we achieve class-incremental learning in online scenario?”
Jiangpeng He, his co-authors and Prof. Zhu proposed a modified knowledge-distillation loss function together with a two-step learning technique to address catastrophic forgetting problem in the challenging online learning scenario. The central idea is to use a base model to supervise the online model to retain old knowledge. Their method outperforms SOTA on both CIFAR-100 and ImageNet datasets even under challenging online scenario.
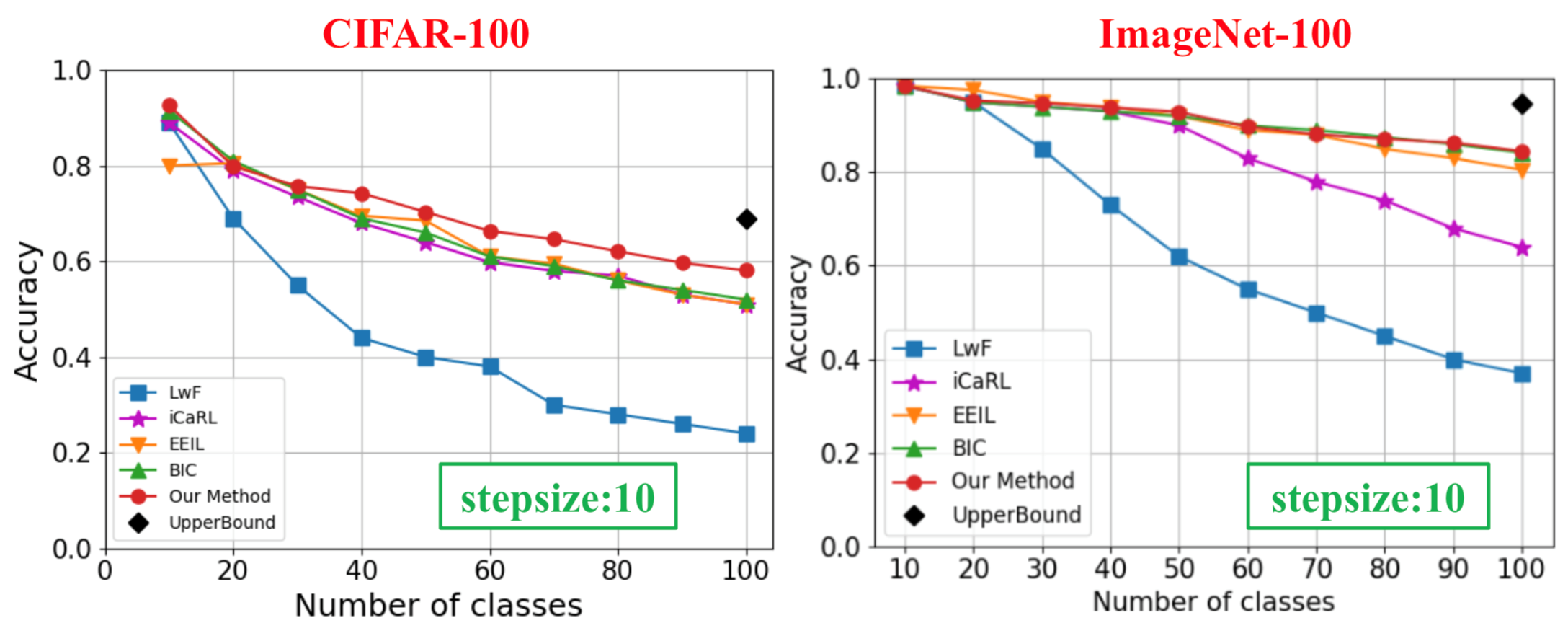
In addition, they also found that current SOTA methods do not take care of the new observations of old class data. ‘’This is very dangerous because we never know the data distribution in real life and when data distribution changes over time, concept drift will happen, then no matter how much effort we put in retaining old knowledge, degradation in performance become inevitable.” said Jiangpeng He. Therefore, they proposed a simple yet effective way to update exemplar set using the mean vector of each new observation. These proposed methods are integrated to introduce a new framework for class incremental learning that is capable of life learning from scratch.
The work was presented in the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, June 2020 (virtual conference due to COVID 19). CVPR is the top-1 conference for computer vision research. The typical acceptance rate is about 20%.
Reference:
He, Jiangpeng, Runyu Mao, Zeman Shao, and Fengqing Zhu. "Incremental Learning In Online Scenario." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13926-13935. 2020.
Manuscript of this paper is available at https://openaccess.thecvf.com/content_CVPR_2020/html/He_Incremental_Learning_in_Online_Scenario_CVPR_2020_paper.html