by Ananya Ipsita | Mar 25, 2025 | 2025, Ananya Ipsita, Karthik Ramani, Runlin Duan, Ziyi Liu
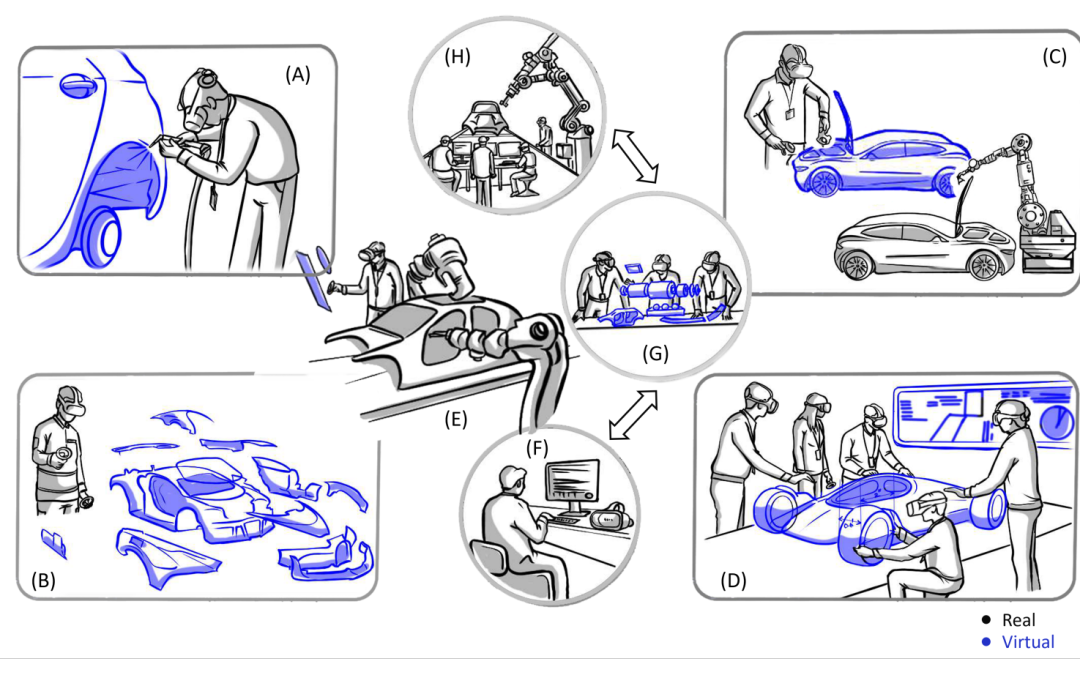
To address the shortage of a skilled workforce in the U.S. manufacturing industry, immersive Virtual Reality (VR)-based training solutions hold promising potential. To effectively utilize VR to meet workforce demands, it is important to understand the role of VR in...
by Min Liu | Mar 11, 2025 | 2025, Karthik Ramani, Min Liu
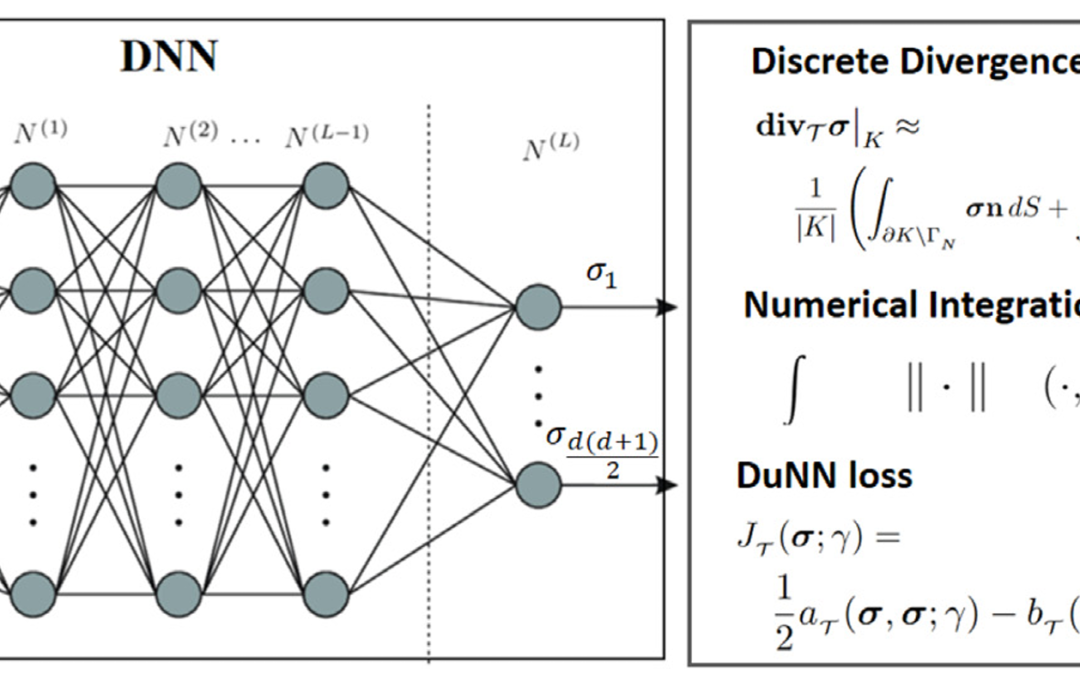
This paper presents the Dual Neural Network (DuNN) method, a physics-driven numerical method designed to solve elliptic partial differential equations and systems using deep neural network functions and a dual formulation. The underlying elliptic problem is formulated...

by Rahul Jain | Dec 1, 2024 | 2024, Asim Unmesh, Karthik Ramani, Karthik Ramani, Rahul Jain, Recent Publications, Subramanian Chidambaram
Computer vision (CV) algorithms require large annotated datasets that are often labor-intensive and expensive to create. We propose AnnotateXR, an extended reality (XR) workflow to collect various high-fidelity data and auto-annotate it in a single demonstration....
by Fengming He | Oct 24, 2024 | 2024, Fengming He, Karthik Ramani, Recent Publications, Xiyun Hu, Xun Qian, Zhengzhe Zhu
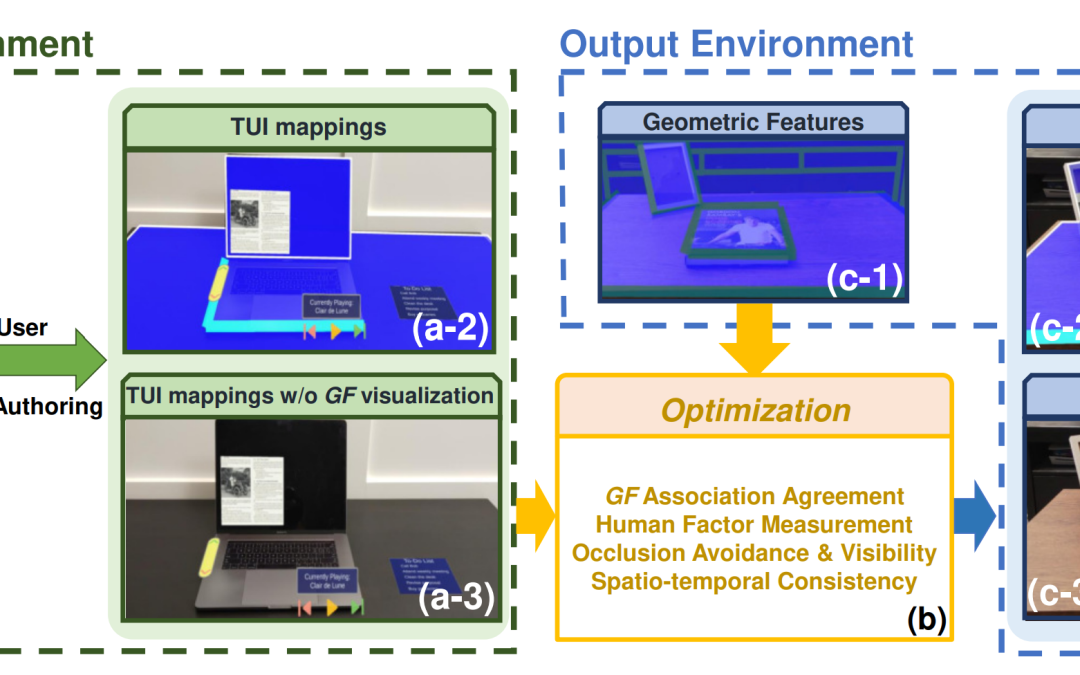
With the advents in geometry perception and Augmented Reality (AR), end-users can customize Tangible User Interfaces (TUIs) that control digital assets using intuitive and comfortable interactions with physical geometries (e.g., edges and surfaces). However, it...
by Hyung-gun Chi | Oct 24, 2024 | 2024, Hyunggun Chi, Karthik Ramani, Recent Publications
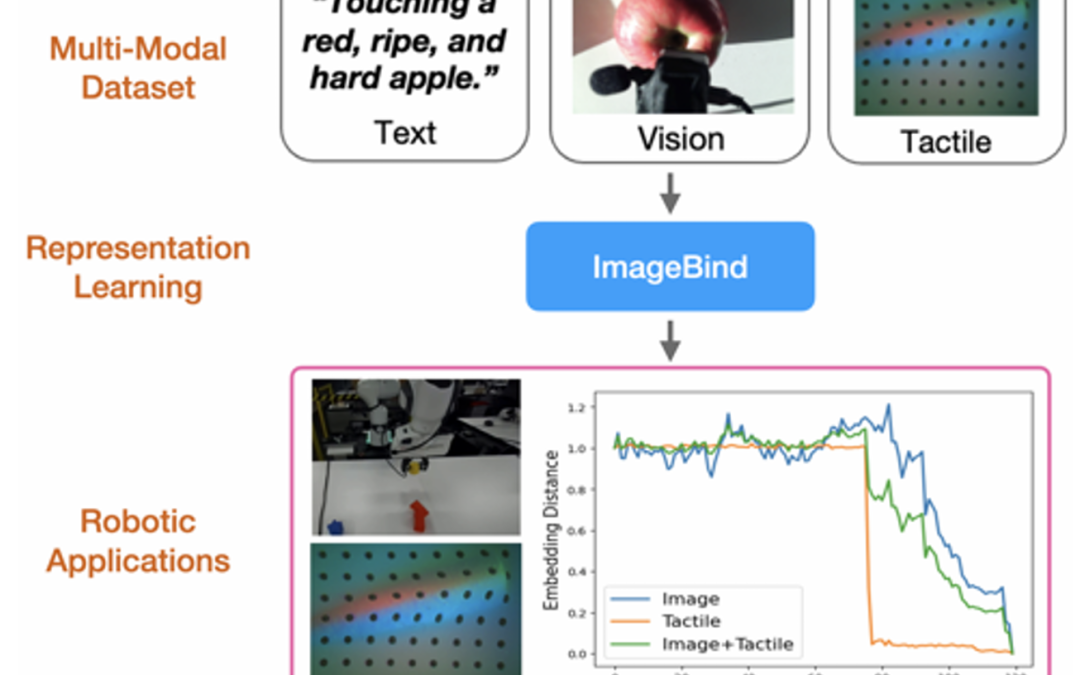
Advancements in embodied language models like PALM-E and RT-2 have significantly enhanced language-conditioned robotic manipulation. However, these advances remain predominantly focused on vision and language, often overlooking the pivotal role of tactile feedback...
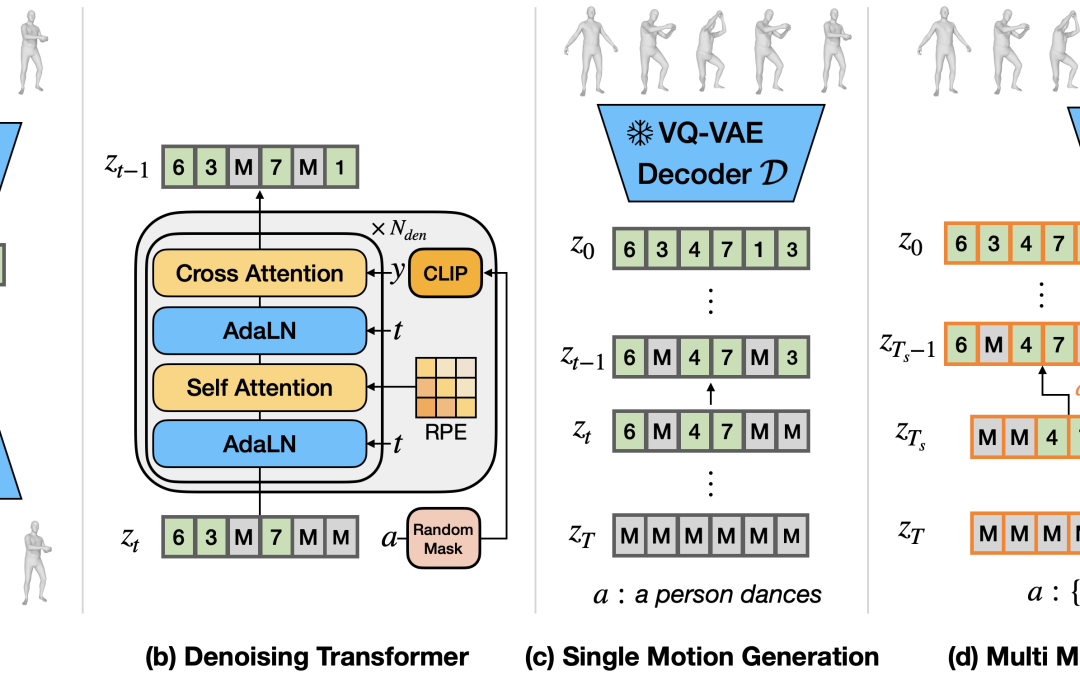
by Seunggeun Chi | Sep 26, 2024 | 2024, Featured Publications, Hyunggun Chi, Karthik Ramani, Karthik Ramani, Publications, Recent Publications, Seunggeun Chi
We introduce the Multi-Motion Discrete Diffusion Models (M2D2M), a novel approach for human motion generation from textual descriptions of multiple actions, utilizing the strengths of discrete diffusion models. This approach adeptly addresses the challenge of...