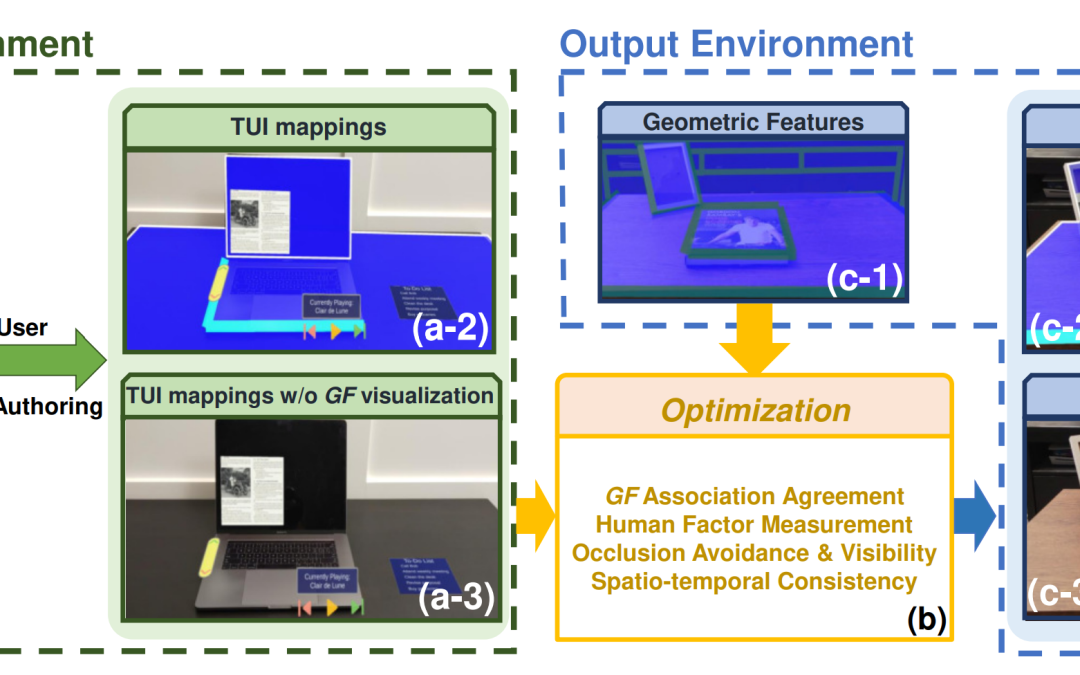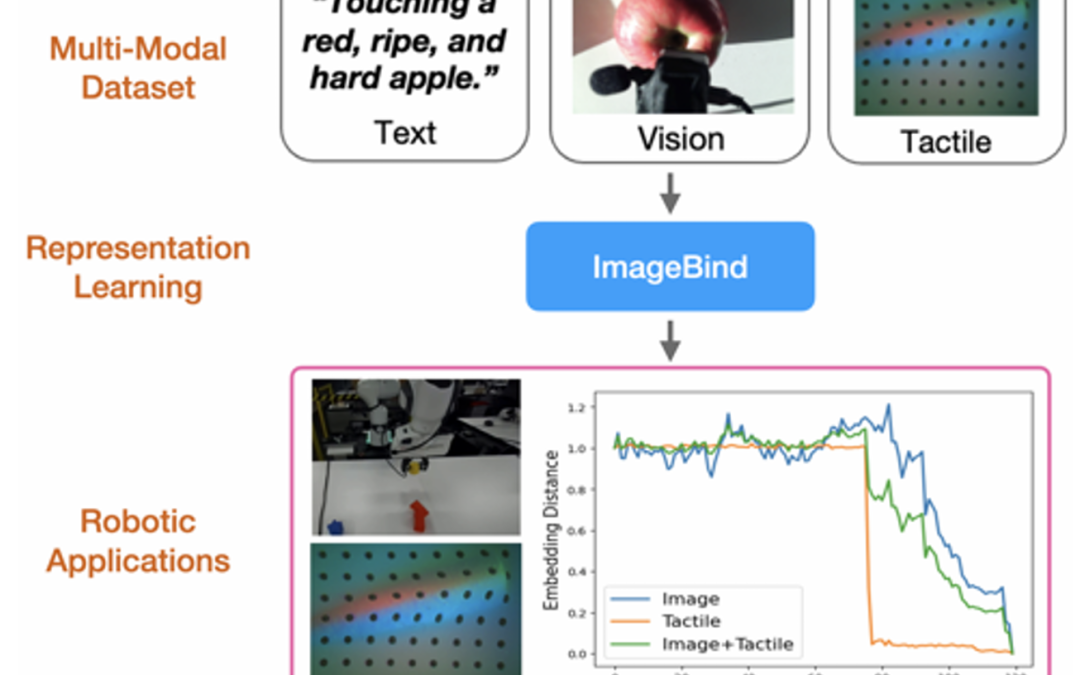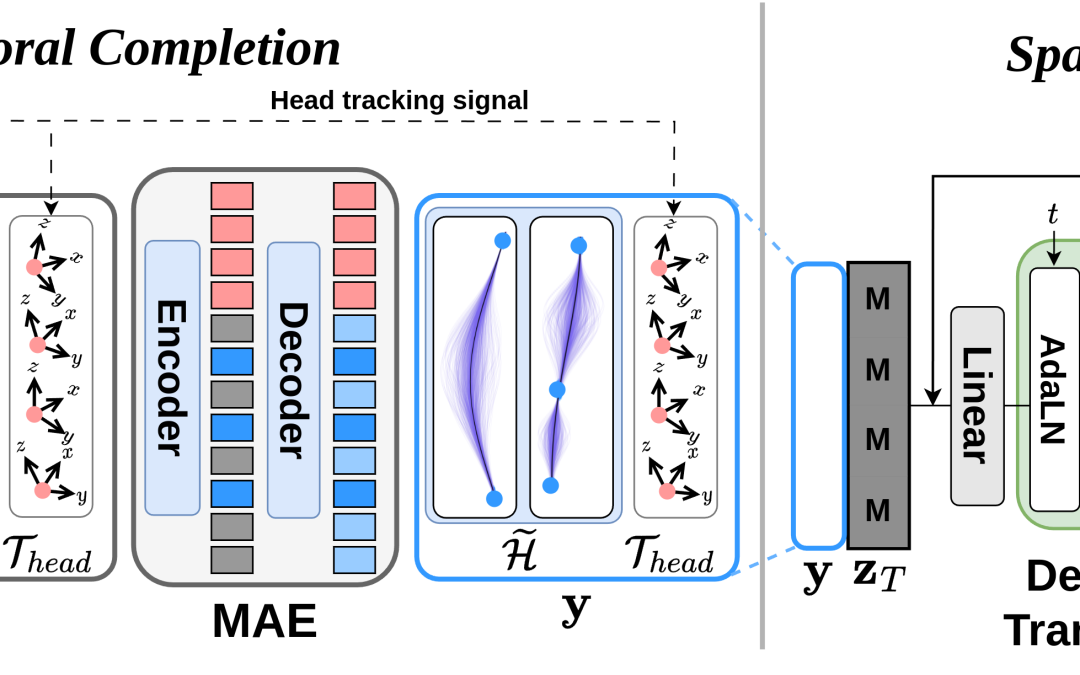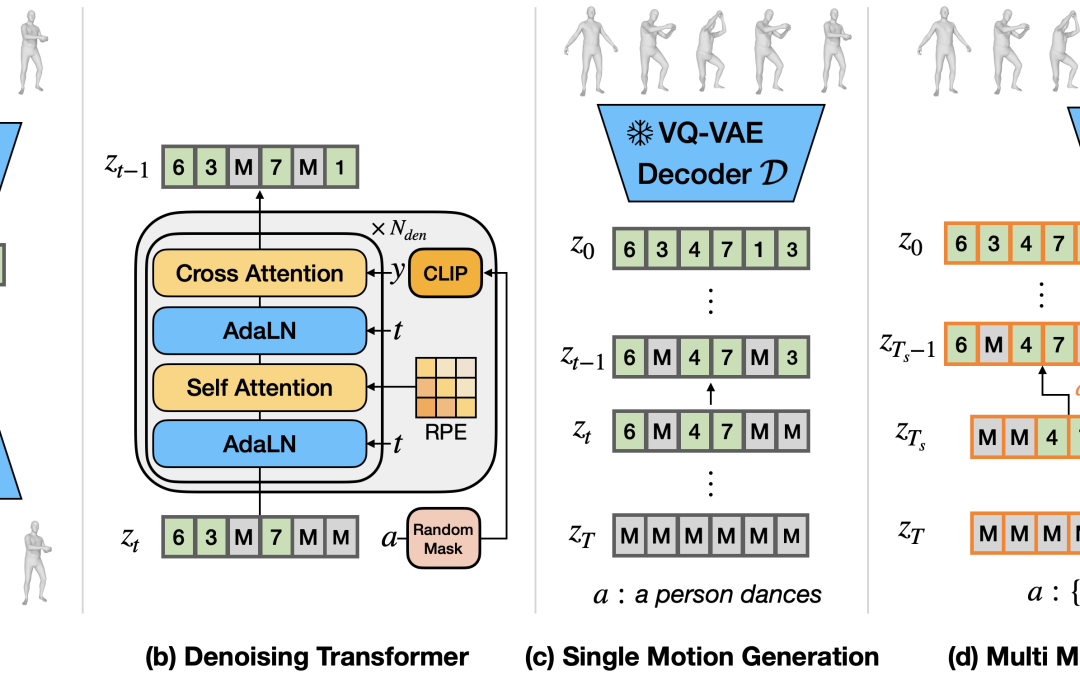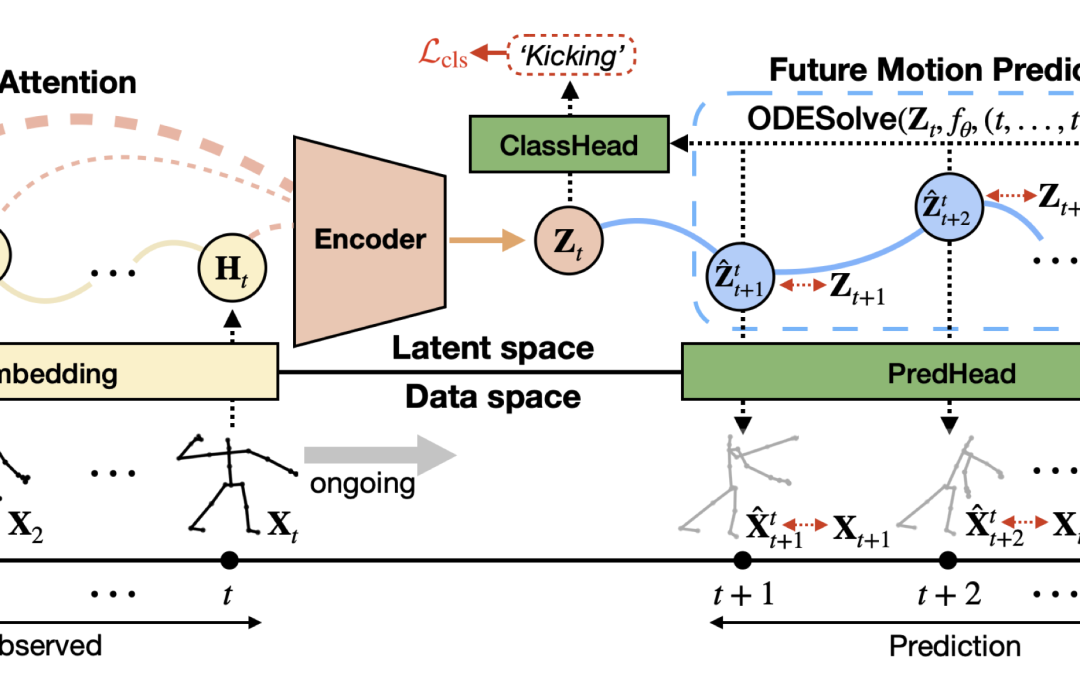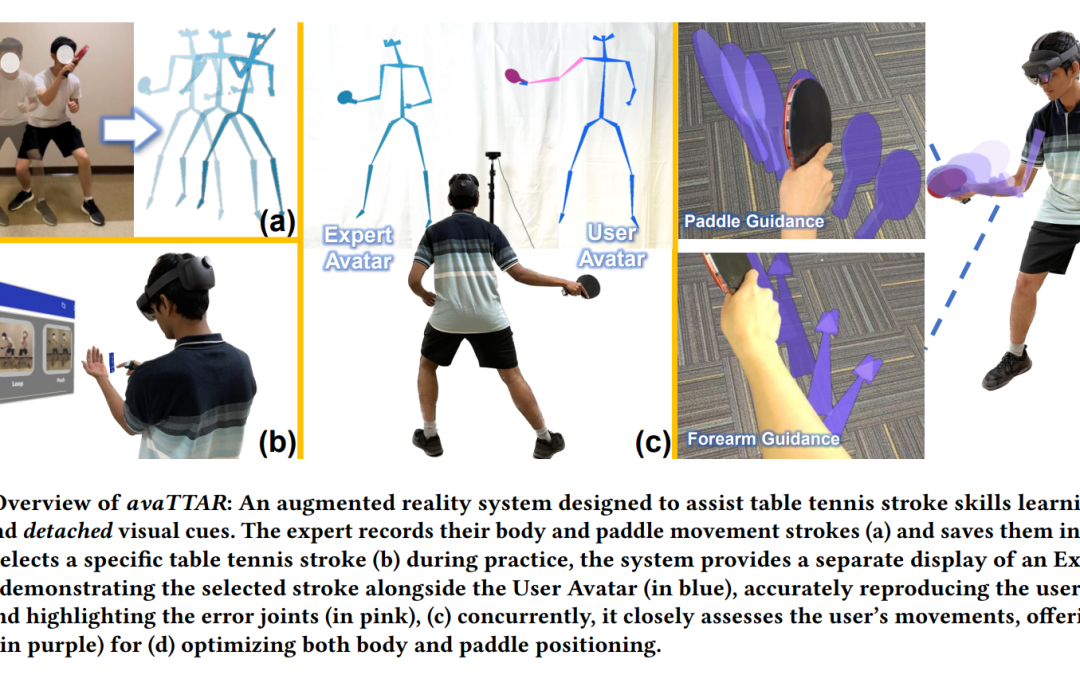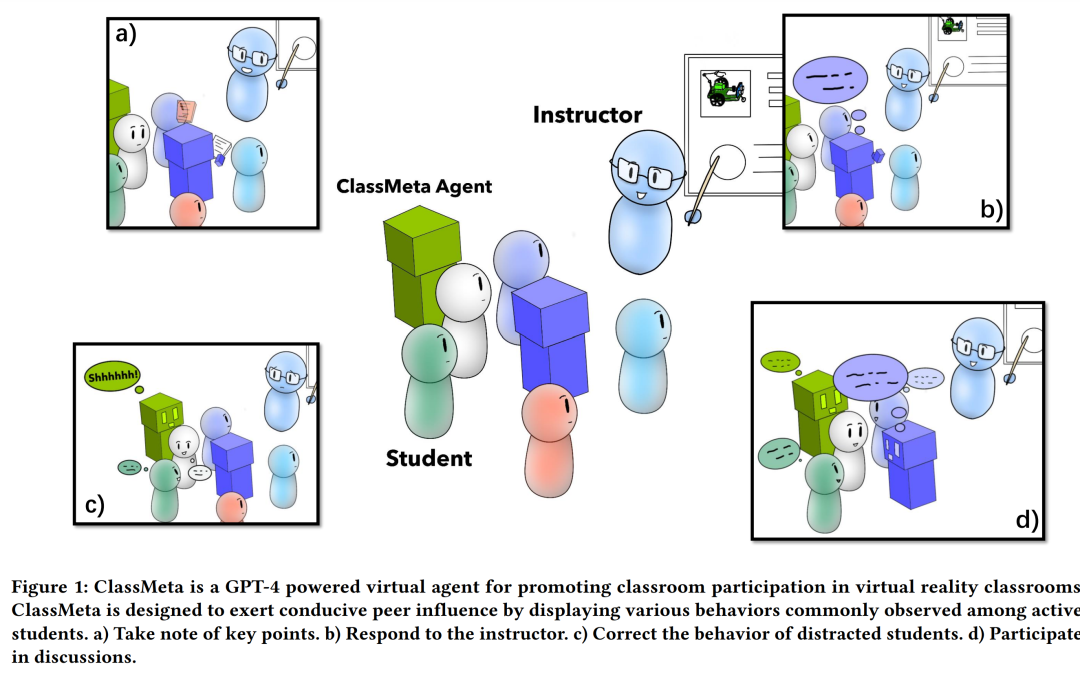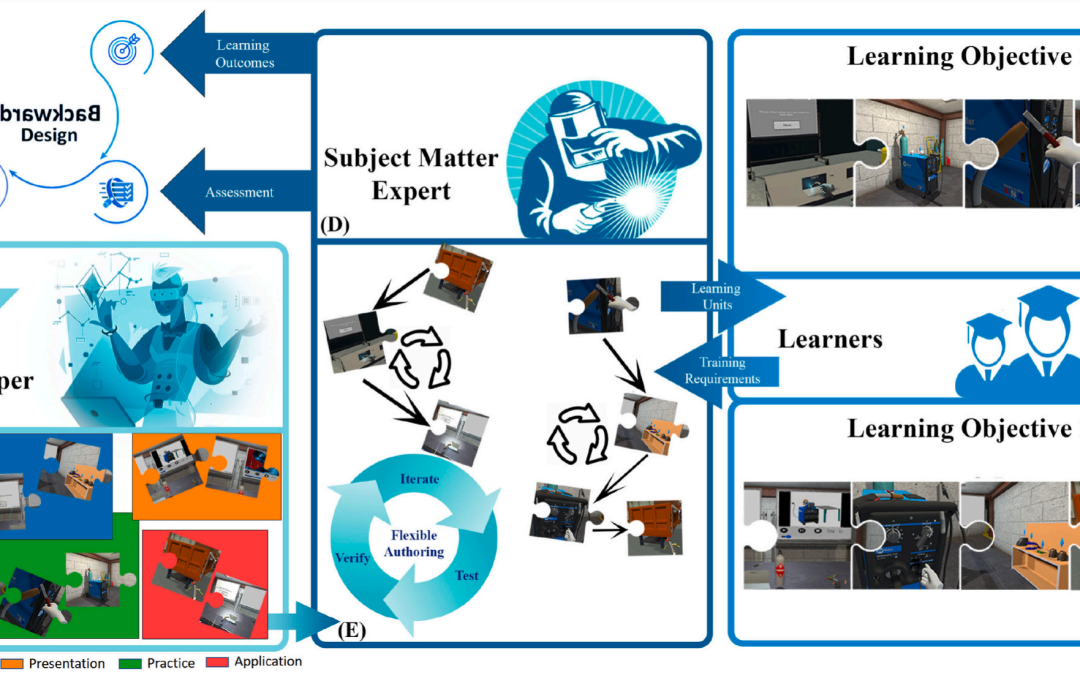
Computers & Education: X Reality 5 (2024): 100074.
Despite the recognized efficacy of immersive Virtual Reality (iVR) in skill learning, the design of iVR-based learning units by subject matter experts (SMEs) based on target requirements is severely restricted. This is partly due to a lack of...