The Visual Computer (2019): 1-15.
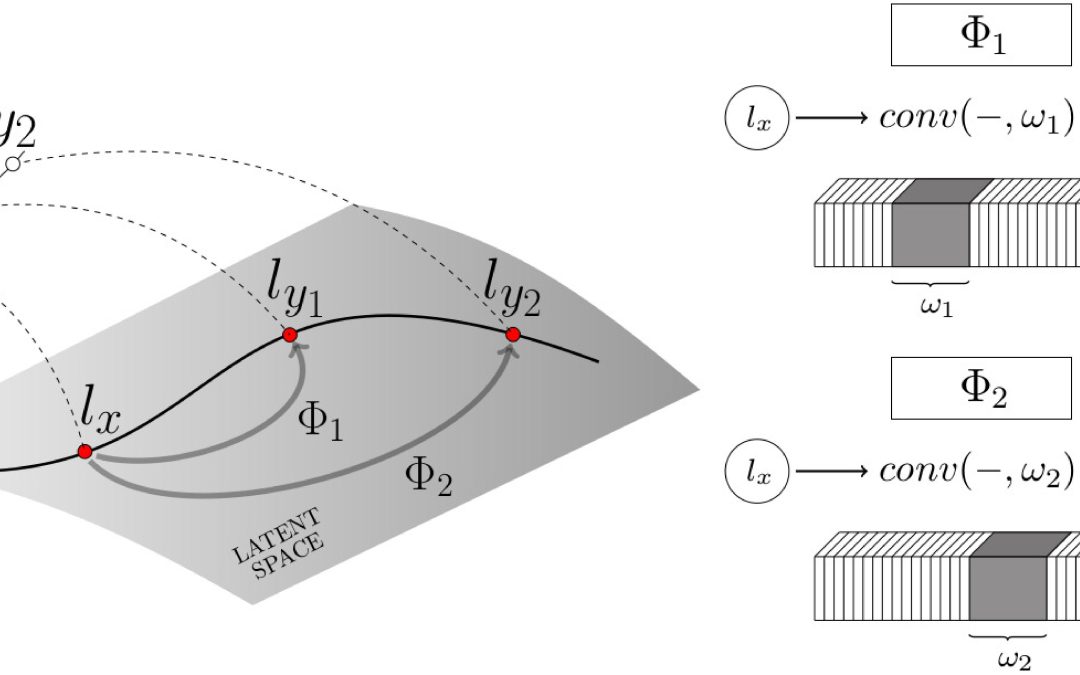
We propose a fully convolutional conditional generative neural network, the latent transformation neural network, capable of rigid and non-rigid object view synthesis using a lightweight architecture suited for real-time applications and embedded...