
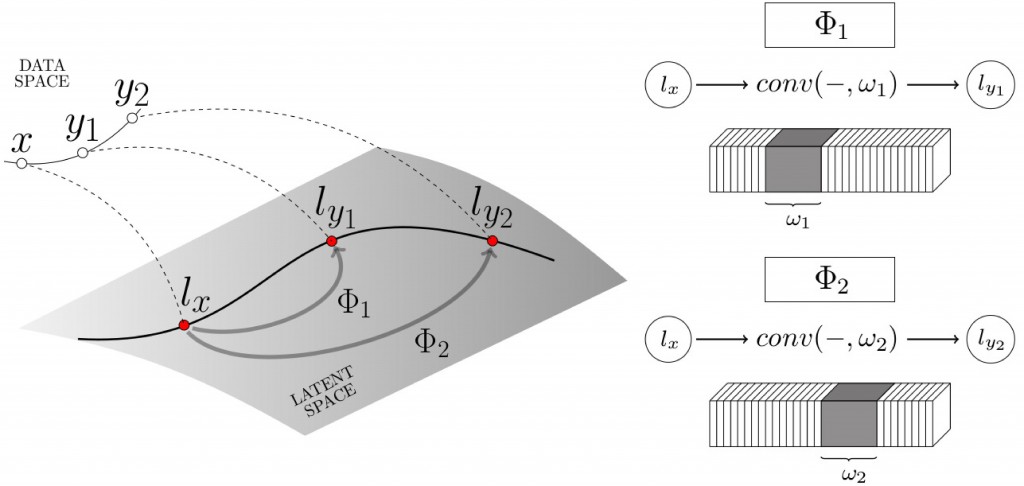
We propose a fully convolutional conditional generative neural network, the latent transformation neural network, capable of rigid and non-rigid object view synthesis using a lightweight architecture suited for real-time applications and embedded systems. In contrast to existing object view synthesis methods which incorporate conditioning information via concatenation, we introduce a dedicated network component, the conditional transformation unit. This unit is designed to learn the latent space transformations corresponding to specified target views. In addition, a consistency loss term is defined to guide the network toward learning the desired latent space mappings, a task-divided decoder is constructed to refine the quality of generated views of objects, and an adaptive discriminator is introduced to improve the adversarial training process. The generalizability of the proposed methodology is demonstrated on a collection of three diverse tasks: multi-view synthesis on real hand depth images, view synthesis of real and synthetic faces, and the rotation of rigid objects. The proposed model is shown to be comparable with the state-of-the-art methods in structural similarity index measure and L1 metrics while simultaneously achieving a 24% reduction in the compute time for inference of novel images.
