{kind=link}
This post is to give the key insights from our just-accepted CVPR 2024 paper:
“Leak and Learn: An Attacker’s Cookbook to Train Using Leaked Data from Federated Learning”
Joshua Christian Zhao, Ahaan Dabholkar, Atul Sharma, and Saurabh Bagchi
Federated learning (FL) is a decentralized learning paradigm introduced to preserve privacy of client data. Despite this, prior work has shown that an attacker at the server can still reconstruct the private training data using only the client updates, the gradients on their local data. These attacks are known as data reconstruction attacks and fall into two major categories: gradient inversion (GI) and linear layer leakage attacks (LLL). Previous works had proven the effectiveness of these attacks in breaching privacy. However, we did not know till now what was the usefulness of the reconstructed data for downstream Machine Learning (ML) tasks — examples of ML tasks are object recognition or video action recognition.
In this paper, we explore data reconstruction attacks through the lens of training and improving models with leaked data. We demonstrate the effectiveness of both GI and LLL attacks in maliciously training models using the leaked data more accurately than a benign FL strategy. Counter-intuitively, this bump in training quality can occur even when reconstruction quality is not great or when only a small fraction of images is leaked. Putting on our good guy hat, we show that these attacks have some fundamental limitations for downstream training, separately for GI attacks and for LLL attacks.
The Important Question
With the onset of deep learning, data has become a valuable commodity. This growth in AI also means that the value of data no longer lies just in breaching privacy of the raw data, but in the ability of the data to be used downstream for creating powerful models. Therefore, one measure of the success of a data reconstruction attack should be whether the leaked data is useful for machine learning training. This question was unanswered till now.
In prior work, leakage had been quantified in the context of breaching privacy by whether there are any identifiable images in the entire reconstructed batch. Given the importance of overall data quality for training models, a sufficient condition for leakage success is no longer if any images are identifiable, but rather the overall usefulness of the leaked data for a downstream training task.
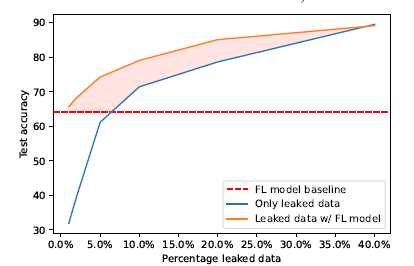
The above figure shows at a high level that if one uses the leaked data to train a model (blue curve), and better still, uses the already trained model (using FL) as a starting point (solid red curve), that can give a big benefit over vanilla FL (dotted red line).

The Next Level of Questions
Viewing data reconstruction attacks through the lens of training models brings up many questions.
- How do models trained with leaked images compare to centralized or federated learning?
- Does the reconstruction quality impact how well models perform when trained on leaked data?
- How does the lack of label matching during reconstruction affect linear layer leakage?
We answer these questions in this work.
The Answers my Friend are (Blowing) in our Paper
Answer to question 1: The table below shows the result for CIFAR-10. For the two attacks (gradient inversion and linear layer leakage), training happens with leaked data. Second column indicates the number of clients in federated learning (FedAVG), the batch size for the gradient inversion attack, and the fully-connected layer size factor for linear layer leakage. Best accuracy is used for FedAVG and final accuracy for all other settings.
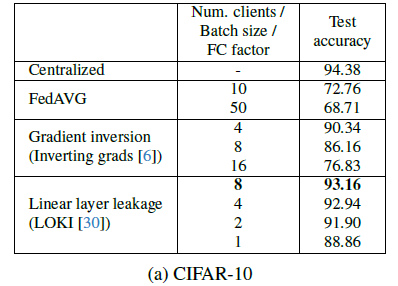
Centralized training achieves a 94.38% accuracy and federated learning achieves a 72.76% and 68.71% peak accuracy with 10 and 50 clients respectively. Centralized and FL indeed provide the upper bound and the lower bound of the accuracy here. Across all attack settings, GI and LLL achieve higher model accuracy compared to vanilla FL. The reconstruction quality of GI is adversely affected by larger batch sizes and in turn also impacts the final model performance.
Answer to question 2: Let us take the case of LOKI, our previous work which defines the state-of-the-art attack in FL. Here as the Fully Connected layer becomes larger (FC factor is higher) then a larger proportion of images is leaked. We see that this has some effect on accuracy of the trained model, but the falloff is not dramatic. Thus, even with reasonably small-sized FC layer to leak the data, it is possible to help in the training of the downstream model.

half the FC layer size has comparable leakage rate to FedSGD.
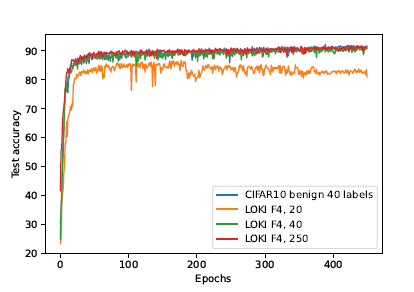
Answer to question 3: This brings out the weak spot of privacy attacks for downstream tasks. For Linear Layer Leakage (LLL) attacks, even if labels are known prior to reconstruction, the LLL process does not match them to the leaked images. As a result, after reconstruction there would be a set of leaked images and labels, where the images are not matched with their corresponding labels. Furthermore, because only a proportion of images in any given batch are leaked for LLL, even with a full set of labels, some labels will not have a leaked image to go with. This can lead to a tedious process of manually labeling leaked images. We can see the effect of semi-supervised learning (SSL, when only some of the labels are known) from the result figure below. Here we see the test accuracy plot of LOKI size factor 4 with the number of known labels being 20, 40, and 250. With 20 and 250 labels, LOKI factor 4 achieves 86.69% and 91.65% peak accuracy. We note that there is a greater variability in accuracy with a smaller number of labels, a trend consistent with other SSL methods.
To Sum
We have explored the effect of leaked data through today’s leading data reconstruction attacks on downstream model training. Our main message is that it is important to also consider the use of data beyond reconstruction quality and image similarity. It is important to consider how far these leaked samples help in a downstream training task. From the experiments, we have seen that current reconstruction attacks are powerful, but still lack in several critical areas. For gradient inversion attacks, the reconstruction quality does pose an issue for training models. For Linear Layer Leakage attacks, the lack of labels poses a large challenge in training models on the data. With a small dataset like CIFAR-10, hand labeling 40 images is not too challenging. However, larger datasets will require more total labels, which would be hard to leak and tedious to label manually. So the glass is half full and half empty, no matter whether you wear a white hat or a black hat.