{kind=link}
Our IEEE Security and Privacy paper shows how to deal with human cognitive biases and still secure interdependent systems (such as, a large-scale system with multiple owners for different sub-systems). We devise a way to incentivize individual stakeholders to place the right level of security investments so that the overall security of the system is steered toward the global optimum.
And show how close to that global optimum is possible to achieve in the face of decentralized decision making. Further, the decision making by individual stakeholders suffers from cognitive biases, such as, considering some high probability events to be less likely and some low probability events to be more likely. For example, we have all encountered folks afraid of flying due to the possibility of a crash (a highly unlikely event, thankfully) and folks who think nothing of being distracted while driving (driving a car is the most dangerous thing many of us will do in our lives).
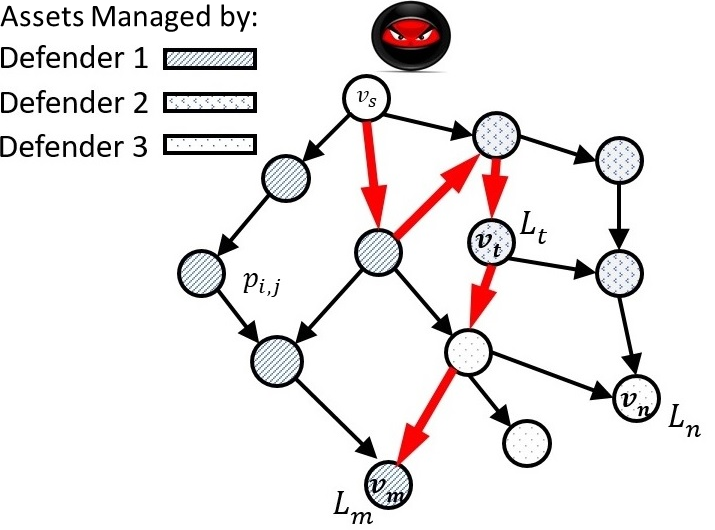
The interdependencies between assets are represented by edges.
An attacker tries to compromise critical assets using stepping-stone
attacks starting from vs. The bold (red) edges show one such attack
path.
Here is the paper:
Mustafa Abdallah, Daniel Woods; Parinaz Naghizadeh (Ohio State University); Issa Khalil (Qatar Computing Research Institute (QCRI), HBKU); Timothy Cason, Shreyas Sundaram, Saurabh Bagchi, “TASHAROK: Using Mechanism Design for Enhancing Security Resource Allocation in Interdependent Systems,” Accepted to the 43rd IEEE Symposium on Security and Privacy (S&P 2022).