Generative Photography
 |
FlowSteer: Conditioning Flow Field for Consistent Image Restoration |
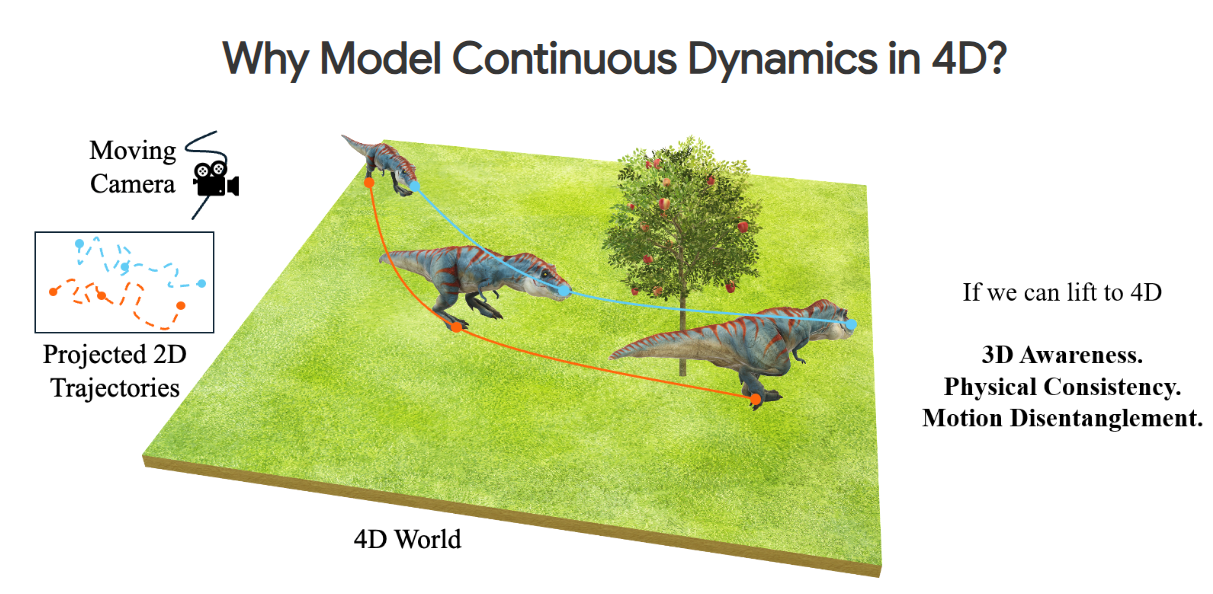 |
Seeing the Unseen World via 4D Dynamics-aware Generation |
 |
NewtonGen: Physics-Consistent and Controllable Text-to-Video Generation via Neural Newtonian Dynamics |
 |
Generative Photography: Scene-Consistent Camera Control for Realistic Text-to-Image Synthesis |
 |
Personalized Generative Low-light Image Denoising and Enhancement |
 |
Generative Quanta Color Imaging |