Robust Machine Learning
Selected Publications
 |
Optical Adversarial Attack |
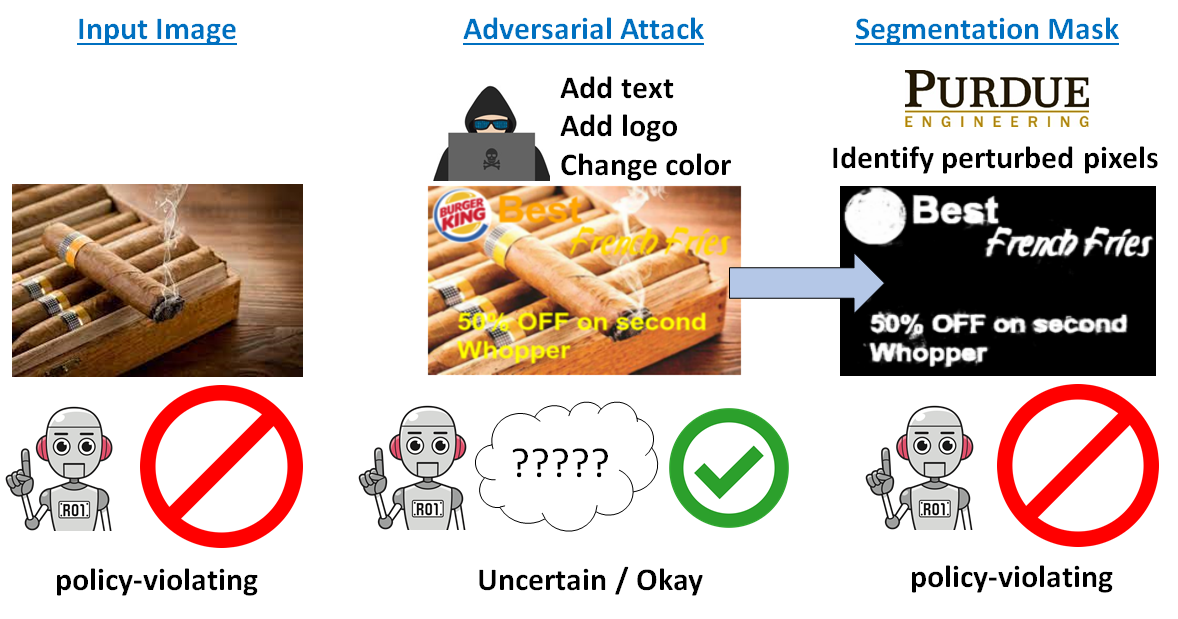 |
Detecting and Segmenting Adversarial Graphics Patterns from Images |
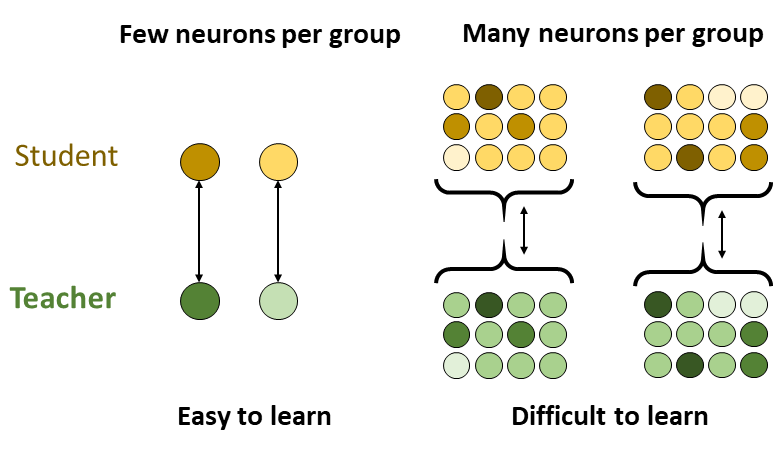 |
Student-Teacher Learning from Clean Inputs to Noisy Inputs |
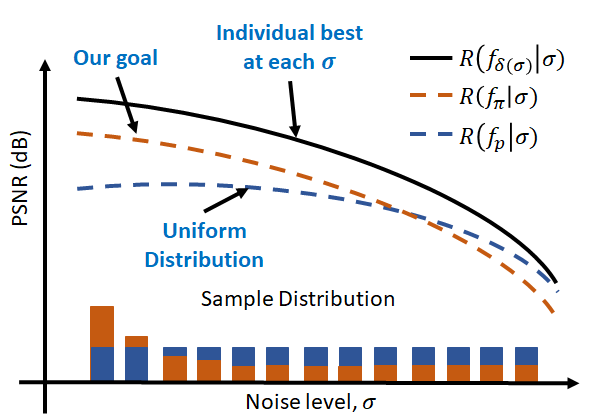 |
One Size Fits All: Can We Train One Denoiser for All Noise Levels? |
 |
ConsensusNet: Optimal Combination of Image Denoisers |