Today’s distributed applications are composed of a large number of hardware and software components. Many of these applications require continuous availability despite being built out of unreliable components. Therefore, system administrators need efficient techniques and practical tools for error-detection that can operate online (as the application runs). Preventing an error from becoming a user-visible failure is a desirable characteristic. Automatically predicting impending failures based on observed patterns of measurements can trigger prevention techniques, such as microrebooting, redirection of further requests to a healthy server, or simply starting a backup service for the data.
Today’s enterprise-class distributed systems routinely collect a plethora of metrics by monitoring at various layers—system-level, middleware-level, and application level. Many commercial and open-source tools exist for collecting these metrics, such as HP OpenView, Sysstat, and Ganglia. A common class of error-detection techniques works as follows. From values of metrics collected during training runs, a model is built up for how the metrics should behave during normal operation. At runtime, a comparison is made between what is indicated by the trained model and what metric values are observed in the system. If there is sufficient divergence between the two, an error is flagged.
Existing approaches toward building error-detection systems based on statistical analysis of runtime metrics suffer from one or more of the following problems:
(a) Their models do not consider relationship between metrics
(b) Some models use only the current snapshot of measurements
(c) The overwhelming majority of techniques do not offer failure prediction.
(d) Existing approaches often consider a restricted set of metrics for modeling.
We describe Augury, a error detection and failure prediction tool that overcomes the problems that are present in existing approaches. Augury addresses the problems by combining the following techniques:
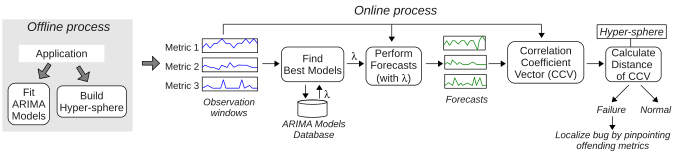
(1) Sequential Multi-Metric Analysis: We address the first challenge by considering a large set of metrics from the system, middleware, and application levels. Augury uses pairwise correlations between metrics to detect errors. With this approach, even when metric values go out of range previously seen before, we will only flag an alarm if the correlation between that metric and another breaks, thus reducing the false positive rate.
(2) Failure Prediction: Augury has a predictive operational mode that uses ARIMA time series model (created offline using training data of typical workloads) and recent measurements to forecast the metric values in the immidiate future. Through this mode, Augury is able to predict impending failures with higher lookahead time, which is desirable since the prediction is only useful when there is enough time for the recovery mechanism to complete before the failure occurs.
We evaluate our approach in synthetic fault injection experiments as well as two real-world cases: StationsStat and Android OS. StationsStat is a multi-tier application that is used to check the availability of workstations on Purdue’s computing labs. The application suffered from an unknown bug that made it fail periodically by becoming unresponsive to end users. Augury predicted the majority of the failure cases with 51 minutes of lookahead time on average. Furthermore, Augury pinpointed the metrics that were mostly associated with the problem in a blind-study in which we did not know the original problem’s root-cause. Subsequently, the developer of the application confirmed that the likely root cause is pointed to by the metrics that Augury determined. In the Android OS case, multiple versions of the Android OS with known bugs are used to evaluate Augury in detecting and predicting failures. Our fault injection experiments are carried out using the application RUBiS