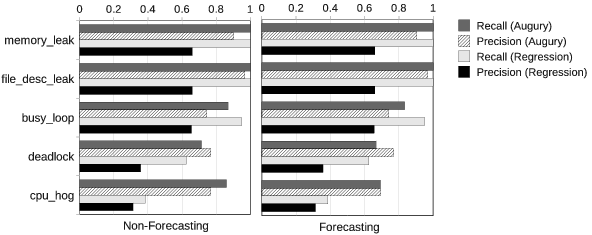
Synthetic fault injection: In these experiments, we were able to achieve high accuracy (both recall and precision). When compared to polynomial regression, our approach produces better accuracy overall (as seen in the chart below).
Performance Result: The amount of time it takes to execute all online steps in Augury is less than 10 msec on average. This includes selecting the best ARIMA models, performing forecasts, and calculating the nearest-neighbor distance of correlation coefficient vectors. We varied the number of metrics being used in the analysis and verified that the overall time grows almost quadratically as we expected—the complexity of calculating correlations for n metrics is O(n2). The results show that it is possible to perform the entire online analysis for more than 800 metrics in less than a second.
Android Case Study: We use two prior-documented bug cases in the Android OS to evaluate Augury. The two bugs are file descriptor leak and HTTPS request hang. In both cases, we developed a program that mimics a realistic workload and activate the bug. As seen in the two charts below, we were able to detect the error soon after the bug is activated.

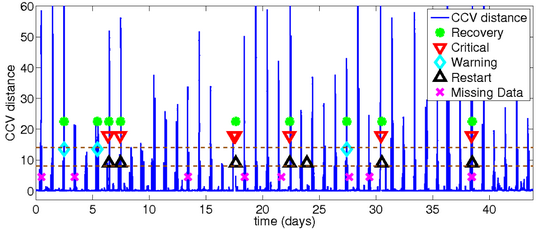
StationsStat Case Study: We evaluate Augury on a real production multi-tier application that is used to check the availability of workstations on Purdue campus. Due to an unknown bug in the application, periodic failures are observed in which the application becomes unresponsive. These failures are made visible to system administrators through alerts of their monitoring system, Nagios, or by user phone calls reporting the problem. When each failure is observed, the application is restarted and the problem appears to go away temporarily. Our result is shown below. Notice how distance peaks occur when failures occur. Thresholds are marked with dashed lines. Failures are critical alerts, warning alerts, missing data events.
Vrisha is a scheme designed to detect and localize scale-dependent bugs in parallel and distributed systems. Scale-dependent indicates that these bugs will only become visible when executed on a system at scale. This property makes the detection and localization of such bugs very difficult in the development and testing phase, where small scale systems are used. It is a common scenario that such bugs are found after the application is deployed on customer's multi-million supercomputers and waste a great deal of time, money and energy.
There are two challenges in designing a detection and localization scheme for scale-dependent bugs in the context of parallel and distributed computing systems. Suppose we have a bug report from the buggy application running on a large system scaled at P. (1) We have no access to a bug-free run on the P-scale system as the bug could be triggered in any run on the system. (2) The bug is invisible on systems scaled less than P. To summarize, we could collect bug-free data, as the bug is invisible, from small scale runs and buggy or bug-free data, which we do not know a priori, from large scale runs.
We designed a special program behavior modeling technique in Vrisha to address the two challenges. Conceptually, a program's execution data is split into two categories: control features are those which entirely determine the observed behavior of a program, such as command line arguments, the number of processors in the system, and the size of input, etc., while observational features are the program behavior that we could collect in the runtime, such as the number of messages sent at each distinct location in the program, the results of conditional branches in the execution, etc. We build a Kernel Canonical Correlation Analysis model between the control and the observational features. With the help of the KCCA model, we can predict what would be the righteous observational features in the large scale run based on the relationship between the control and the observational features collected at small scale runs. With this capability of behavior predication, bug detection at scale becomes a easy task of comparing the predicted result and the actual value and flag a bug candidate whenever the deviation is larger than a predefined threshold (through training with bug-free data to make sure no false positive would be caused by the threshold).
