Inside NEMO5
Input and Output
A NEMO5 simulation needs only 2 input files:
- Input Deck
- Material Parameter File
The input deck is parsed using boost::spirit. The material parameter file is parsed using a custom-made parser. At this stage of the development the geometry construction happens internally in NEMO5, and the simulated device is specified in the input deck. Interested in how obscure they look? Click here to obtain an input deck for a 3D effective-mass simulation of a GaAs quantum dot. Click here to obtain the needed material parameter file. More examples and explanations can be found at the NEMO5 User Support and Distribution Group - access is free.
Atomistic datasets can be saved in various formats. For distributed grids Silo should be used. The Silo file format is based on HDF5 and is recommended by visualization groups for fast and parallel reading and writing of large-scale simulation results. For smaller, non-distributed datasets the VTK file format can be chosen. Lastly the XYZ, PDB and OpenDX formats are available for certain types of output.
1D X-Y type datasets are saved in simple ASCII format for easy post-processing, e.g. with Matlab. Continuum datasets such as the shapes of Brillouin zones are saved in the VTK format. More information can be found on this chart.
Numerical Solvers
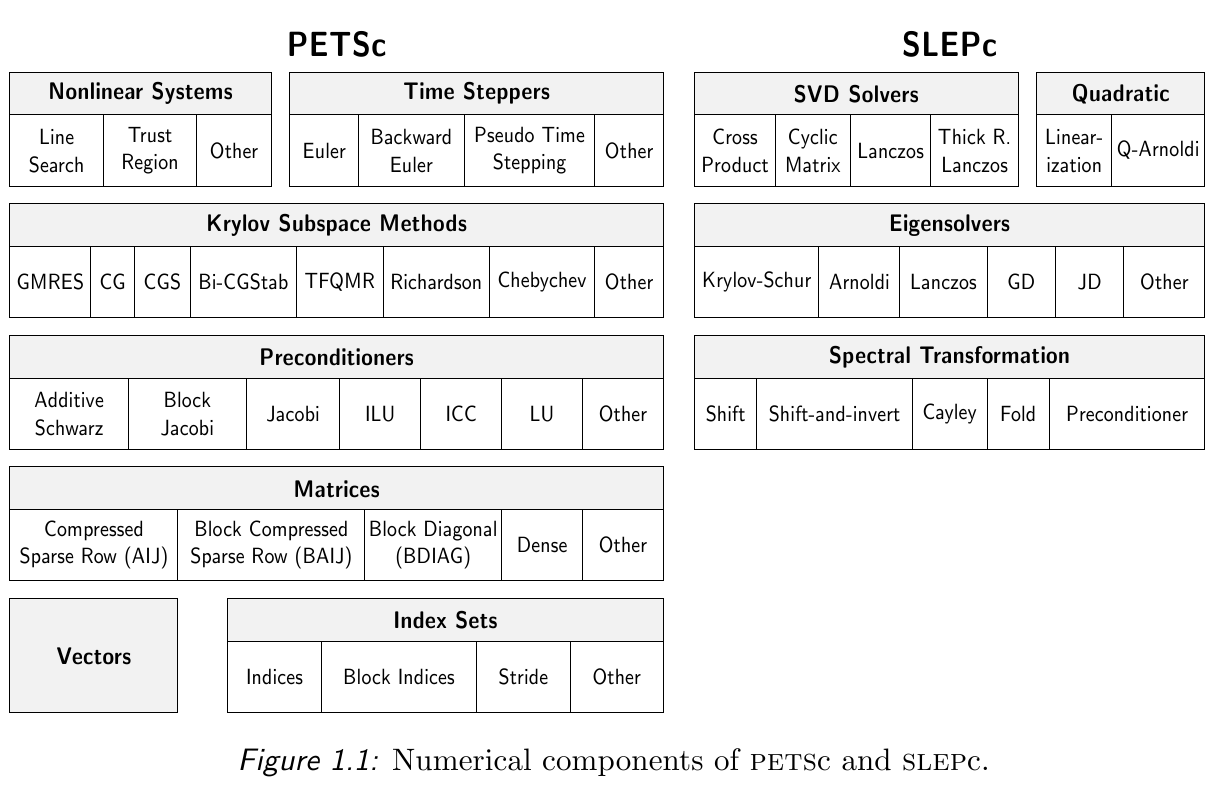
NEMO5 outsources the numerical methods largely to PETSc (Portable, Extensible Toolkit for Scientific Computation). PETSc provides distributed matrix and vector classes as well as a broad range of numerical algorithms for the solution of large linear and nonlinear sparse (and dense) equation systems. PETSc also provides convenient interfaces to other solvers such as LAPACK and the parallel LU factorization libraries MUMPS and SuperLU.
Built upon PETSc is SLEPc (Scalable Library for Eigenvalue Problem Computations) which is employed for eigenvalue problems.
The Quickhull library and a small library for tensor manipulations are employed for smaller tasks.
Parallelization
One of the core capabilities of NEMO5 is the extreme parallelization of the code. By parallelization we mean the distribution of the computational burden onto many CPUs which are able to communicate with each other. This is achieved by using the well-known MPI protocol. NEMO5 has been installed and used on various supercomputers, amongst which the mighty Jaguar, Ranger, Rossmann and Coates.
Further information on parallelization in NEMO5 can be found here. Examples for scaling can be found here.