Mars Mosaic Generation Timing on 39 800MHz CPUs
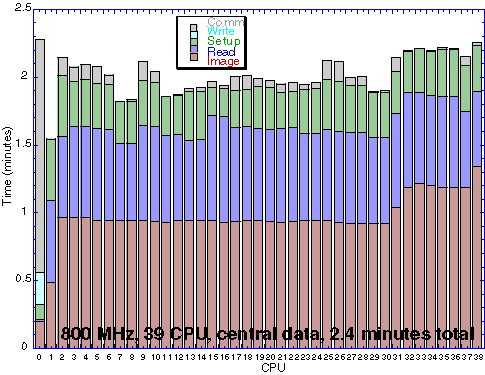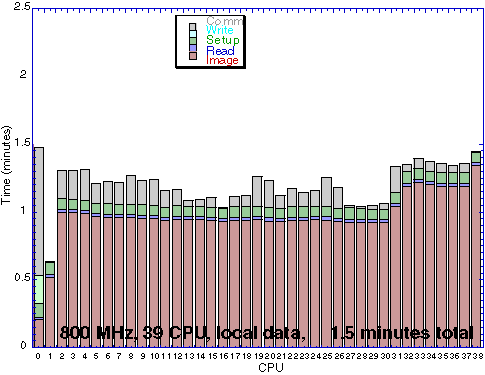
Timing Anaysis on 39 CPUs with central data:
The figures above shows a diagram for the time spent in the set-up, the initial file reading, image processing, communication and final image writing for each individual CPU for run on 39 800MHz Pentium III CPUs. With this many CPUs only about 1.5 minutes is spent on the actual image processing. The remaining 0.8 minutes are mostly spent on set-up and reading of the original images. The reading of all the input images by all the CPUs from the front end disk leads to a dramatic bottle neck of the overall computation.
Timing Analysis on 39 CPUs with local /tmp data:
The heavy disk load on the front end can be eliviated by copying all the images to the local /tmp disk of the computation nodes. The second graph in the above animation shows the virtual elimination of the previously significant read time. Interestingly we have also significantly reduced the time declared as set-up. We believe that this is due to the fact that during the set-up time all the input files are probed for their individual size and coordinates, which are needed to define the size of the final mosaic. This double access to the images became apparent to us in the analysis of this data. Additional improvements to the algorithm to only read a file and/or its header once are clearly possible.
The copying of all the individual images to the local disks comes with a significant price in performance: a rcp shell command takes about 7 minutes to execute. Clearly that is not an efficient solution. Possibly faster I/O hardware such as a RAID disk or a parallel file system might be solutions to this problem.
Looking at the final performance data with the local data one can see again a load balancing problem. However, sqeezing out the last 10-20% performance by balancing this load and reducing the total time from 1.5 minutes to may be 1.3 minutes may proove to be laborious and not necessary as the platform this code will be run on during the mars landing is not completely defined at this time.
Acknowledgements:
This work was sponsored by the TMOD technology program under the Beowulf Application and Networking Environment (BANE) task.The original VICAR based software is maintained in the Multi-mission Image Processing Laboratory (MIPL). The work was performed in a collaboration between Gerhard Klimeck, Myche McAuley, Tom Cwik, Bob Deen, and Eric DeJong