Increased deployment of high-speed computer networks has made distributed systems ubiquitous in today’s connected world forming the backbone of much of the information technology infrastructure of the world today. We increasingly face the challenge of failures due to natural errors and malicious security attacks affecting these systems. Downtime of a system providing critical services in power sys-tems, space flight control, banking, air traffic control, and railways signaling could be catastrophic. It is therefore imperative to build low latency detection systems whose goal is to determine when a failure has occurred.
a detection system is to be complemented with efficient diagnosis system whose goal is to determine which component was the root cause of the failure. In this discussion we follow the classical definition of fault, error, and failure. A fault is an invalid state or a bug underlying in the system, which, when triggered, becomes an error. A failure is an external manifestation of an error manifested to the user. A failure in a distributed system may be manifested at an entity that is distant from the one that was originally in error. This is caused by error propagation between the different communicating entities which has been well documented in practical distributed systems [3][4]. The role of the diagnosis system is to identify the entity that originated the failure. The diagnosis problem is significant in distributed applications that have many closely interacting components, since the close interactions facilitate error propagation.
Design challenges/requirements
There are several challenges to the problem of designing a detection system which can handle failures in the distributed systems of today. First, many existing systems run legacy code, the protocols have hundreds of participants, and systems often have soft real-time requirements. A common requirement is for the detection system to be non-intrusive to the payload system implying that significant changes to the application or to the environment in which they execute are undesirable or infeasible (for example, for third party binary applications). This requirement rules out executing heavyweight detectors in the same process space or even in the same host as the application entities. While it may be possible to devise very optimized solutions for individual distributed applications, such approaches have limited generalizability and significant effort is to be invested for deploying the infrastructure for a different application. Trying to make changes to a particular protocol also requires in-depth understanding of the code which may be unavailable.
For the diagnosis system as well, there are several requirements in addition to the above-mentioned ones. It is desirable that the diagnosis system operates asynchronously to the payload system so that the system’s throughput does not suffer due to the checking overhead. Second, the diagnosis system should not be intrusive to the payload system. This rules out the possibility of making changes to the application components or creating special tests that they respond to. Instead, this argues in favor of having the application components be viewed as a blackbox by the diagnosis system. This is in sharp contrast to the probing based approach that has been the subject of much development in the field [2][5]. In this approach, the application components are subjected to test requests from the diagnosis system which they respond to and the responses are used to determine the health of the component. This approach may not be suitable in certain environments due to the fact that in times of failure, it may be inadvisable to stress the application components additionally. Also, the state of the component when it originated or propagated the error may be different from the current state, which is being tested.
Our Solution: The Monitor System
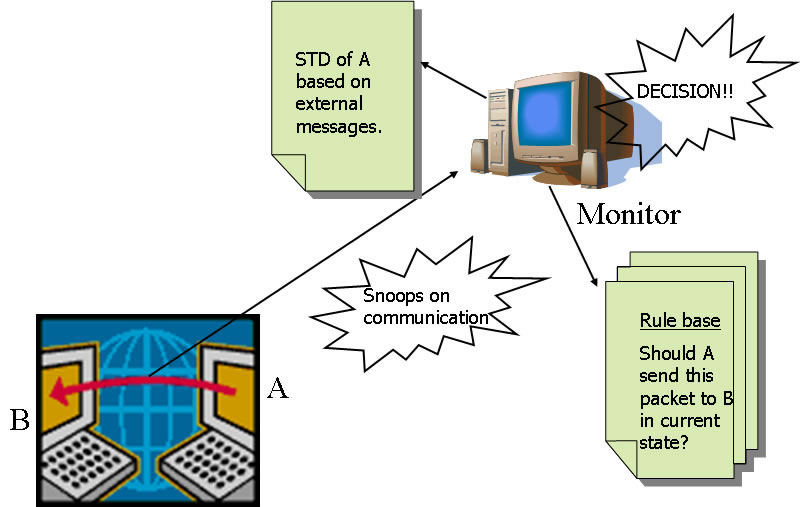
We have developed the Monitor system for the detection and diagnosis of failures in distributed systems. Our design segments the overall system into an observer or a Monitor system and an observed or a payload system (the application). The Monitor system comprises multiple Monitors and the payload system comprises potentially a large number of protocol entities (PEs). The Monitors are said to verify the PEs. The Monitors are designed to observe the external messages that are exchanged between the PEs, but none of the internal state transitions of the PEs. The Monitors use the observed messages to deduce a runtime state transition diagram (STD) that has been executed by the PEs. The deduced STD is necessarily less complete than the actual STD executed the PE since internal transitions cannot be observed and also some of the external transitions may be missed by the Monitor due to the losses in the environment. Next, pre-specified rules in a rulebase are used to verify correctness of the behavior based on the reduced STD. The rules can be either derived from the protocol specification or specified by the system administrator to meet QoS requirements. The system provides a rich syntax for the rule specifications, categorized into combinatorial and temporal rules (valid only for specific times in the protocol operation) and optimized matching algorithms for each class of rules. The rule syntax is derived from temporal logic actions (TLAs) with simplifications to aid in runtime matching and additions to specify domain specific failure behavior.
Upon detection, the diagnosis process is initiated. During normal operation, the causal relation among the PEs is deduced from the send-receive ordering of the messages. Each such causal path is considered a candidate for propagation of the error. The likelihood of the path for error propagation is computed based on several runtime variables, such as, the reliability of the PE, the reliability of the link between the PEs, the characteristic of the PE is masking errors rather than propagating them. For diagnosis, the PEs are not exercised with additional tests, since that would make the Monitor system more invasive to the application protocol. Instead, a state that has already been deduced by the Monitors during a normal operation through the observed external messages is used for the diagnostic process. The runtime parameters mentioned above do not have to be pre-specified in the environment; rather they are learned through observations. Prior knowledge may be used to pre-seed the values.
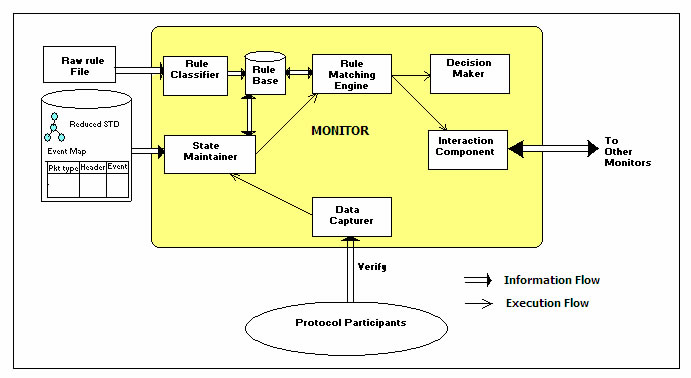
The Monitor architecture is hierarchical. A low-level Monitor, called a Local Monitor (LM), directly verifies a PE, whereas a higher level Monitor, called an Intermediate Monitor (IM), matches rules that span multiple LMs. This can be used to verify correctness properties that depend on multiple components. This is in contrast to some approaches [1] that conclude overall system correctness based on local correctness of all the components. We assume that failures may occur in the Monitor system as well and use replication to mask them. We enforce a hybrid failure model on the Monitors through an existing distributed security kernel—the Trusted Timely Computing Base (TTCB) built by our collaborators from the University of Lisbon.
Demonstration of the Monitor System
The Monitor system has been demonstrated on several applications, some from our sponsors. These include:
- A streaming video application running on a reliable multicast protocol called TRAM installed on the Purdue campus-wide network
- Three-tier e-commerce system from Sun Microsystems
- Virtualized server environment from IBM
The combination of the application-generic part and the application-specific part in the Monitor makes it ideally suited for deployment in different applications. We are currently in discussion about application of the technology to NASA-JPL (Mars Rover missions) and HP (data center operations).
Current Directions of Research
We are researching how the Monitor can be applied to high throughput applications in which the rate of incoming messages that have to be examined is too high for the Monitor’s capacity. We have demonstrated in our SRDS 07 paper that sampling can be used to alleviate the problem somewhat. We are now examining if a smart sampling and an automatic partitioning of the load among multiple Monitors can meet our requirement.
A second thrust of the research is minimization of the state space that the Monitor needs to examine and maintain for its fault tolerance functionality.
Current Students: Ignacio Laguna, Fahad Arshad (PhD)
Collaborators: Miguel Correia, Paolo Verissimo (University of Lisbon), Gautam Kar (IBM Research)
Past Students: Gunjan Khanna (PhD), Mike Cheng, Padma Varadharajan (MS)
Papers: See here.
References
- M. Zulkernine and R.E. Seviora, “A Compositional Approach to Monitoring Distributed Systems,” IEEE Dependable Systems and Networks, pp. 763-772, 2002.
- I. Rish, M. Brodie, S. Ma, N. Odintsova, A. Beygelzimer, G. Grabarnik, K. Hernandez, “Adaptive Diagnosis in Distributed Systems,” in IEEE Transactions on Neural Networks (special issue on Adaptive Learning Systems in Communication Networks), vol. 16, no. 5, pp. 1088-1109, September 2005.
- J. Lin, S.Y. Kuo, “Resolving error propagation in distributed systems,” Information Processing Letters 74, 5-6, pp. 257-262, 2000.
- Arshad Jhumka, Martin Hiller, and Neeraj Suri, “Assessing Inter-Modular Error Propagation In Distributed Software,” Symp. on Reliable Distributed Systems (SRDS), pp. 152-161, 2001.
- R. Buskens and R. Bianchini Jr., “Distributed On-Line Diagnosis in the Presence of Arbitrary Faults,” Proc. 23rd Int’l Symp. Fault-Tolerant Computing (FTCS ’93), 1993.
|
