Fast Vision-Guided Mobile Robot Navigation using Model-Driven Reasoning and Prediction of Uncertainty
The approach incorporated in FINALE for vision-guided mobile robot navigation using a geometric map of the environment is a combination of model-based reasoning and Kalman filtering. This approach enables us to design robust reasoning and control architectures for vision-guided mobile robot navigation in indoor environments. The robot is capable of autonomously navigating in hallways at speeds around 8 m/min using vision for self-location and sonars for collision avoidance. The performance of this robot is not impaired by the presence of stationary or moving objects in the hallways. The robot simply treats everything that is not in its geometrical model base as visual clutters. By maintaining models of uncertainties and their growth during navigation, the robot is able to place bounds on where it should look for important visual landmarks; this gives the robot immunity against visual clutter.


Highlights of the FINALE architecture can be summarized as follows:
• Model-based reasoning and control architecture for navigation.
• 3D geometrical model of an environment.
• Prediction of uncertainties for motion control and visual observation.
• Vision-guided navigation at an average speed of 8 m/min.
• Moving and stationary unknown obstacles avoided using ultrasound.
Overall Architecture of FINALE
The figure below depicts the model-based reasoning and control architecture of FINALE. A human supervisor provides a rough estimate of the initial robot position and the goal position to the robot. Given these initial and goal positions, the Task Organizer organizes the overall control of navigation on a real-time basis by monitoring status reports from other modules in the system. The Task Organizer first requests the Global Motion Planner to create a global path from the current position to the goal position. When the Global Motion Planner returns the path consisting of a sequence of linear translational and rotational moves, the Task Organizer requests the Local Motion Controller to navigate the robot on the planned path, avoid obstacles, and monitor the growth of uncertainty in the robot position. The Obstacle Detector continuously uses an ultrasonic sonar ring mounted in front of the robot to acquire the range information about obstacles. When an obstacle is detected, the Local Motion Controller reduces the speed of the motion and finds a free space for motion so that the robot can successfully avoid the obstacle.
The Uncertainty Manager continuously monitors the positional uncertainty of the robot every 500 msec, in terms of the mean vector and the covariance matrix of the robot position vector. If the positional uncertainty is too large for subsequent motions, the Local Motion Controller issues a self-location request to Task Organizer and stops the motion. Upon receiving the request for self-location, the Task Organizer first requests the Perception Planner to determine the best viewing angle to perform self-location based on the number of visible landmarks in a scene expectation map. If the current orientation is not suitable for the self-location exercise, the Perception Planner will produce a motion command that will lead the robot to a better view with a larger number of visible landmarks. Once the robot rotates to the direction determined by the Perception Planner, the Self-Location Module starts a self-location exercise by first obtaining a camera image from a single TV Camera. On detecting that the self-location process has started, the Task Organizer issues a restart motion command to the Local Motion Controller.
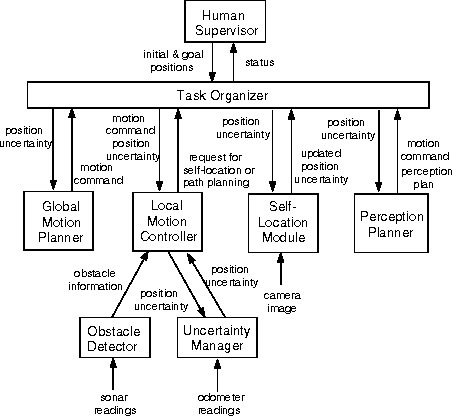
Figure: Overall architecture of FINALE.
Vision-Based Self Location
We will briefly explain how the Self-Location Module performs a vision-based self-location with the help of a 3D CAD model of the environment and the prediction of motion uncertainties. The figure below shows the process of our self-location algorithm. Using a CAD model of the environment and an initial estimate of the predicted mean values of the robot position vector, FINALE first generates a scene expectation map (expectation view) from the camera viewpoint. The following figure shows the expectation map with white lines superimposed on an actual image taken by the camera mounted on the robot. From this expectation map, line segments whose lengths in the view are larger than a prespecified threshold are selected as visible model landmarks (features) so as to be easily extracted from an image. A key element of this vision-based navigation is the propagation of the robot position uncertainty into both the camera image and the feature space in which many of image features used for model matching are easily extracted. In fact, the locational uncertainty of model landmark features in the camera image (expectation map) can also be predicted by the mean vector and the covariance matrix. Such a propagation can be realized by propagating the prediction error covariance of the robot position vector into both the camera image and the feature space, using the Jacobian matrices of the transformations involved. The uncertainty propagated into the camera image bounds the regions where the model landmarks should exist in the camera image. For example, we are able to define such a region by applying an appropriate threshold to the covariance. We will call this region the uncertainty region. in the camera image. Similarly, we can propagate the robot position uncertainty to a feature space such as the Hough space. The Hough space, formed by the Hough transform, is specified by two parameters (rho, gamma) to represent a line in the camera image -- the perpendicular distance rho from the image origin to the line, and the orientation angle gamma of the normal vector to the line.

Figure: Actual procedure of vision-based self location.
For each model landmark feature, image features are extracted only from its uncertainty region in the camera image. Since we use the Hough transform to extract image features, this extraction process is facilitated by applying the Hough transform to only uncertainty regions in the Hough space.
Due to visual occlusions and background conditions, the line extraction by the Hough transform may extract more than one image feature in the uncertainty region. (See the following figure that includes many chairs in the hallway.) In order to precisely estimate the robot position vector, we need to find a correct correspondence between model landmarks and image features. Our algorithm performs an optimal correspondence search using parametric reasoning for model and image feature relations. This algorithm, performing a constrained search, is verified to be robust even in the presence of occlusion and a large displacement of expectations and actual views.
To show how precisely FINALE can calculate the exact position of the robot, the following figures show the expectation map, and the result of self location exercise. White lines in the right figure indicate the reprojection into the camera image of those model landmarks that were used by the Kalman filter for finding correspondences with the image features. Therefore, these figures show the accuracy of the vision-based self location.


Figure: Expectation map and result of self-location.


A. Kosaka and J. Pan, "Purdue Experiments in Model-based Vision for Hallway Navigation'', Proceedings of Workshop on Vision for Robots in IROS'95, pp.87-96, 1995. [ps, 4.2MB]
A. Kosaka, M. Meng, and A. C. Kak, "Vision-Guided Mobile Robot Navigation Using Retroactive Updating of Position Uncertainty," Proceedings of the IEEE International Conference on Robotics and Automation, Atlanta, 1993.
A. C. Kak "Model-Based Vision for Mobile Robot Navigation Using Metrical and Non-Metrical Models of Environment," 1993 SPIE Conference on the Applications of Artificial Intelligence, Orlando, April 1993.
A. Kosaka and A. C. Kak, "Fast Vision-Guided Mobile Robot Navigation using Model-Based Reasoning and Prediction of Uncertainties," (Invited Paper) Computer Vision, Graphics, and Image Processing -- Image Understanding, pp. 271-329, November 1992.
A. Kosaka and A. C. Kak, "Fast Vision-Guided Mobile Robot Navigation Using Model-Based Reasoning and Prediction of Uncertainties," Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, Raliegh, 1992.
M. Meng and A. C. Kak, "Fast Vision-Guided Mobile Robot Navigation using Neural Networks," Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, 1992.
A. Kosaka and A. C. Kak, "Fast Vision-Guided Mobile Robot Navigation Using Model-Based Reasoning and Prediction of Uncertainties," Working Notes of the AAAI Spring Symposium on Control of Selective Perception, Stanford University, March 25-27, 1992.
Akio Kosaka and A. C. Kak, "Data-Fusion and Perception Planning for Indoor Mobile Robot Navigation," Proceedings of the Second International Symposium on Measurement and Control in Robotics, Tsukuba Science City, Japan, November 1992.

• FUZZY-NAV: A Vision-based Robot Navigation Architecture using Fuzzy Inference for Uncertainty-Reasoning

FINALE