OpenMPC: Extended OpenMP Programming and Tuning for GPUs
Motivation
OpenMPC - OpenMP extended for CUDA
Overall Compilation Flow
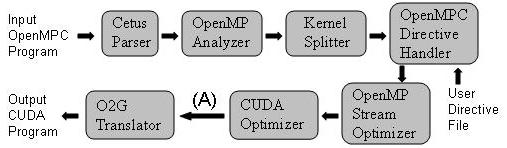 Fig. 1. Overall Compilation Flow. When the compilation system is used for automatic tuning, additional passes are invoked between CUDA Optimizer and O2G Translator, marked as (A) in the figure (See Figure 2) |
- The Cetus Parser reads the input OpenMPC program and generates an internal representation (Cetus IR).
- The OpenMP Analyzer recognizes standard OpenMP directives and analyzes the program to find all OpenMP shared, threadprivate, private, and reduction variables that are explicitly and implicitly used in each parallel region. The analyzer also identifies implicit barriers by OpenMP semantics and adds explicit barrier statements at each implicit synchronization point.
- The Kernel Splitter divides parallel regions at each synchronization point to enforce synchronization semantics under the CUDA programming model.
- The OpenMPC-directive Handler annotates each kernel region with a directive to assign a unique ID and parses a user directive file, if present. The handler also processes possible OpenMPC directives present in the input program.
- The OpenMP Stream Optimizer transforms traditional CPU-oriented OpenMP programs into OpenMP programs optimized for GPGPUs, and the CUDA Optimizer performs CUDA-specific optimizations. Both optimization passes express their results in the form of OpenMPC directives in the Cetus IR.
- In the last pass, the O2G Translator performs the actual code transformations according to the directives provided either by a user or by the optimization passes.
Prototype Tuning System
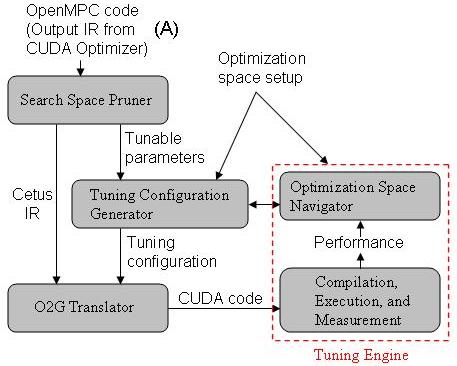 Fig. 2. Overall Tuning Framework. In the figure, input OpenMPC code is an output IR from CUDA Optimizer in the compilation system (See Figure 1) |
- The search space pruner analyzes an input OpenMPC program plus optional user settings, which exist as annotations in the input program, and suggests applicable tuning parameters.
- The tuning configuration generator builds a search space, further prunes the space using the optimization space setup file if user-provided, and generates tuning configuration files for the given search space.
- For each tuning configuration, the O2G translator generates an output CUDA program.
- The tuning engine produces executables from the generated CUDA programs and measures the performance of the CUDA programs by running the executables.
- The tuning engine decides a direction to the next search and requests the to generate new configurations.
- The last three steps are repeated, as needed.
Publications
Seyong Lee and Rudolf Eigenmann, OpenMPC: Extended OpenMP Programming and Tuning for GPUs , SC10: Proceedings of the 2010 ACM/IEEE conference on Supercomputing (Best Student Paper Award), November 2010.
Seyong Lee, Seung-Jai Min, and Rudolf Eigenmann, OpenMP to GPGPU: A Compiler Framework for Automatic Translation and Optimization , Symposium on Principles and Practice of Parallel Programming (PPoPP'09), February 2009.
Software Download
Funding

This work is supported in part by the National Science Foundation. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.