Stack
Learning goals
You should learn how to:
- REFRESH: Use the C address operators
(
*,&,[…],->),malloc(…),free(…), and Valgrind to manage memory. You will be using these a lot this semester. - Implement a stack data structure.
- Reduce the storage and time overhead that results from using
malloc(…)(andfree(…)) to allocate (and deallocate) a linked list node for every element in a stack.
Overview
The stack data structure is an important building block for many algorithms you will see in this class and beyond. It stores a sequence of data, but conceptually, we access the data primarily by pushing (adding) or popping (reading and removing) values one at a time from one end of the sequence.
The expectation with a stack is that pushing (adding) values and popping (reading/removing) values are both constant time (O(1)) operations.
The simplest way to implement a stack is with an array. However, since the length of an array is fixed at the time it is allocated, the stack cannot grow beyond the space that was initially allocated for it. For applications where the size is not known in advance—i.e., size depends on inputs or events not known until the program runs—implementing a stack as an array runs the risk of running out of space. When that happens, the only solution is to replace the array with a larger array and copy all of the data. An alternative is to start with a very large array, but that would waste space, and it may be difficult to predict the absolute largest amount of space that might be required.
The strategy you probably learned in ECE 26400 is to use a linked list with one node for each
value on the stack. Every time a value is pushed onto the stack,
malloc(…) is called once to allocate space for the node.
Likewise, every time a value is popped, free(…) is called.
For programs that operate on modest amounts of data, that strategy is fine. However, as
the amount of data becomes larger, the overhead may eventually affect performance in two ways.
Time efficiency may suffer due to large numbers of calls to
malloc(…) and
free(…).
These standard library functions take care of
dividing up memory on the heap—a segment of your program's memory space—and allocating blocks
to your program or other parts of the system. They have been well-optimized and give
adequate performance for many applications, but for large numbers of small allocations, we can do
better by allocating larger blocks of memory.
Space efficiency may suffer due to the overhead of many linked list nodes. Whereas in an array,
all of the space is used for the values stored, a linked list must store the
.next address for each node. Furthermore, every block of memory allocated by
malloc(…) requires some overhead for managing the space, and there
is usually a minimum size for an allocation block. For example, on some systems, allocating
a single byte using malloc(…) will consume 32 bytes in memory.
References
- The quest for the fastest linked list − Ivica Bogosavljević
- Comparison of List Implementations − CS3 Data STructures & Algorithms − OpenDSA
Block Stack
You will create a stack data structure that uses a hybrid approach for memory allocation.
Like the linked list stack, it will use linked list nodes allocated with
malloc(…). However, each node will contain an array of
(potentially) many values. Essentially, each node contains an inner stack that is array-based.
Initially, the empty stack has no linked list nodes. Upon pushing one value, a linked list node is added. We'll call this a block node. The block node has multiple slots for values. Initially, just the first slot is taken with the value just pushed. If you push a second value, then two slots in the block node. The block node keeps track of how many slots are empty (available). If you keep pushing values, eventually the block node will become full. After that, the next time a value is pushed, your code will add an additional block node.
The structure was explained in lecture on Thu 9/7/2023.The user of your block stack code can choose how big each block (block node) should be. Since the user should not need to understand the inner workings of your code in order to use it, they simply specify the maximum number of bytes per block node. You then calculate how many values can fit into that amount of memory.
The block node struct type (called
BlockNode includes some fields to maintain the structure, such as a
.next field (for the linked list) and .num_empty_slots to
keep track of how many slots for values are still available in this node. It also has
enough room for just one value. For simplicity, it will be an int.
(In real life, it would likely be something more.)
Storage for each BlockNode
Although the BlockNode type has space for only one value, we will
allocate additional space after it (in heap memory) to accomodate additional values.
If we allocated space only sufficient for one BlockNode and then wrote
to, say, node -> values[3], it would be a buffer overflow. However, if
we allocate enough room after it, then we can treat that array of size 1 as if it were
an array of some other size (.num_values_per_node).
Suppose we had .num_values_per_node == 8.
If we allocated only sizeof(BlockNode) bytes for each block node, we would have room
for only one value per block node. That would not work.

But if we allocate more than sizeof(BlockNode) bytes, then we have room for
additional elements. We will essentially be writing past the end of an array—usually a no-no—but
we have taken steps to ensure that it is safe.

It is as if the .values field had been declared as
int[8] (array of 8 int)—even
though it is still most certainly declared as
int[1] (array of 1 int).
(Do not modify the BlockNode struct type or anything else in stack.h.)

Overall structure
The first function you will create is
create_empty_stack(…). It creates a
struct object, called a Struct. That's not the block node. It is
a simple wrapper that makes the rest of this simpler for the user (i.e., someone
using your code to do something else). The Struct will have just two
fields: .top (address of the top BlockNode) and
.num_values_per_node (capacity of each BlockNode).
To the user of your code, the Stack is the stack (data structure).
That is all they should need to know.
Here is an example. The ▒▒▒ is the maximum number of bytes the user
wants each block to consume. In other words, the user is saying that your code
should allocate heap memory in increments of no more than ▒▒▒ bytes at a time.
We will push the numbers 101 to 110 onto the stack, in ascending order.
// Create empty stack
Stack stack = create_empty_stack(▒▒▒);
// Push the numbers 101 to 110
for(int value_to_push = 101; value_to_push <= 110; value_to_push++) {
push(&stack, value_to_push);
}
This will result in the following structure.
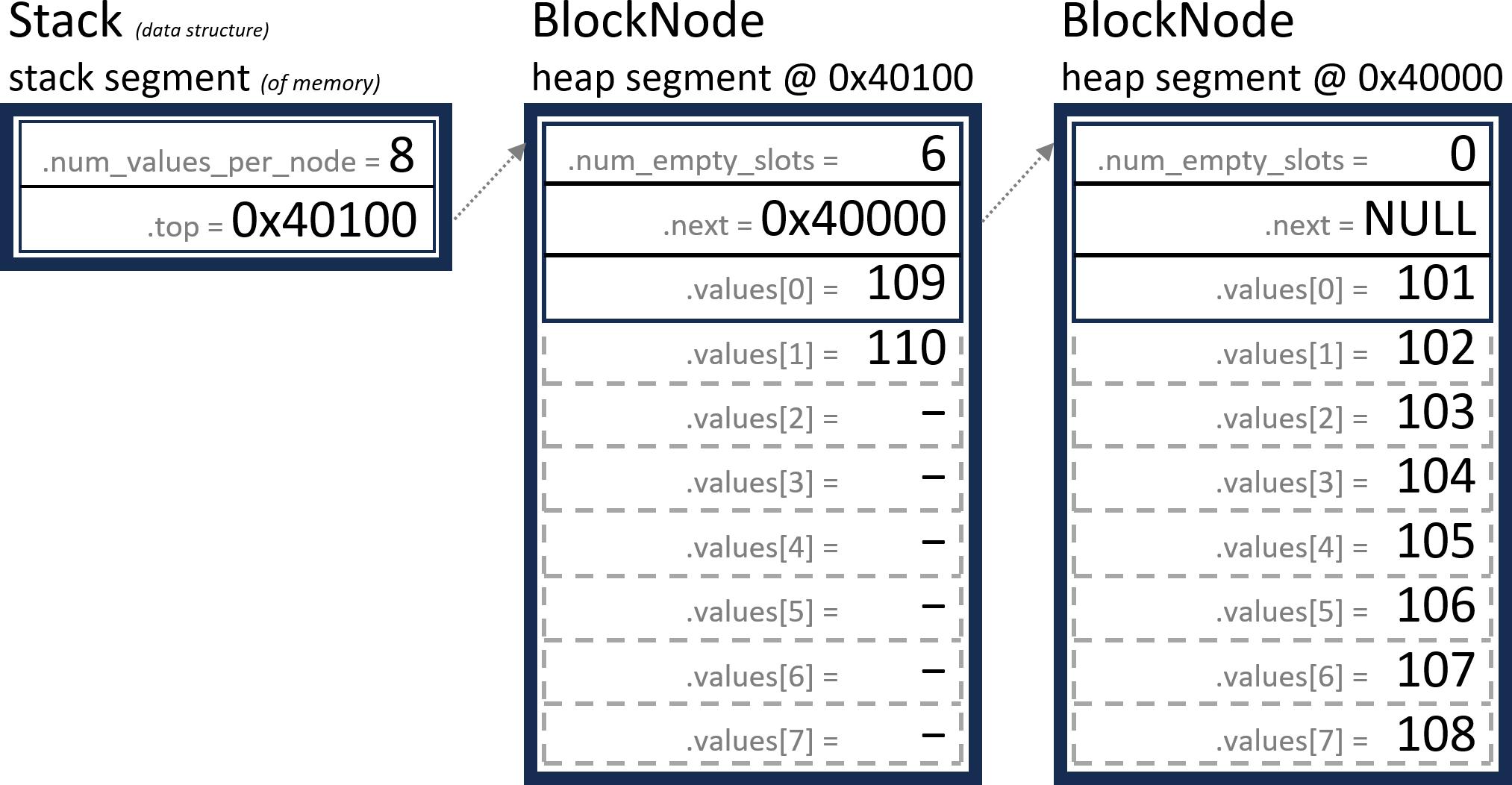
This is just a more efficient way of storing the following conceptual stack (data structure).

Note: The code snippet above is incomplete; it does not free the memory allocated
for the stack. To free, you will call empty(&stack). If the stack
is empty (i.e., is_empty(&stack)), then you do not need to call
empty(…), but doing so should not cause any problems.
Getting Started
Set up your environment.
Go to the Setup page and follow the instructions.
Create a directory for this course.
you@ecegrid-thin1 ~/
$ mkdir 368you@ecegrid-thin1 ~/
$ cd 368Get the starter code.
you@ecegrid-thin1 ~/368/
$ 368get hw02 you@ecegrid-thin1 ~/368/
$ cd hw02you@ecegrid-thin1 ~/368/hw02
$
stack.h is the header file. It declares the functions that will be defined in stack.c, the
implementation file. Those functions will be used in test_stack.c, the test file.
It also includes the struct type definitions for Stack
and BlockNode, and a constant MIN_NODE_BLOCK_SIZE_BYTES.
You also have two more files, stack_utils.c and stack_utils.h. Those are used only in the test file (test_stack.c), to make testing easier. Do not use them in stack.c or stack.h.
Test-driven development
You will use a very simplified adaptation of test-driven development (TDD), a popular software engineering process. We have provided you with several pre-written tests to start with, but the overall flow should be the same.
- Start with a test.
- Write just enough code to pass that test—without trying to solve anything else.
- Run your test(s).
- If the test failed, fix your code until your test(s) pass(es).
- Repeat, adding one new test each time. At every stage, run all of your tests to make sure you have not broken functionality that worked previously.
Always start with a very easy test case. Get it working perfectly, tested, and submitted before you move on to another test case. Do not start by trying to solve the most interesting part of the assignment.
Your code should never be in a "broken" state for more than about 10-15 minutes. That way, if something is broken, it is very likely due to something you changed in the last 10-15 minutes. It makes it easier to find. Also, you will always be working from a position of strength. With each piece you build, you will be starting from something that works.
If you get stuck and are looking at a mess of code that doesn't work that you've been hacking on for over an hour, our advice will often be to go back to the last time it did work. If you have not been following TDD, then that means starting over from the beginning.
Here's another way to look at it. If you somehow lost your mind and do not finish the rest, you should have something that will likely get at least some credit. With each test you add and get working, you will have more of the ultimate functionality working. That tends to yield more partial credit. (Of course, 100% credit should always be your target, and it is definitely attainable by anyone in this class.)
Normally, you would use a unit-test framework to structure your tests. For simplicity,
we will rely on assert(…). You will notice that whenver
an assert(…) fails (i.e., condition is false), your
executable prints the line number of the assert(…) that failed, and the
text of the condition that failed. (Note: If you ever see (void*)0), it
is referring to NULL.)
Requirement: incremental submissions
You are required to submit at least 6 times, at least 10 minutes apart with significant differences in the code—and the amount of working functionality—between these submissions. You are strongly encouraged to submit more often than that. But if we check all of your submissions, assuming we are testing thoroughly, we should get at least 6 different scores. (The number of unique scores is not an explicit requirement. As long as you make a good faith effort to do incremental submissions, as you go, we will make sure you get the credit.)
This is to help you. We know that many students have an ingrained habit of focusing on the interesting part of an assignment first. We also know that trying to finish everything in one chunk leads to bad things (e.g., difficult bugs, code spaghetti, all-nighters, low scores, etc.). The further you go as a programmer, the bigger the projects will be. Trying to finish big chunks all at once becomes increasingly difficult and prone to risk. We are trying to guide you.
In addition, we hope that this requirement gives a bit of resistance to inappropriate uses of GenAI (i.e., ChatGPT, etc.) so that at the end of the semester. Those tools are designed to make fully working code. We want to always know for sure that people who do well in Purdue ECE programming courses are good programmers.
Compile
To compile:
you@ecegrid-thin1 ~
$ cd 368you@ecegrid-thin1 ~/368
$ cd hw02you@ecegrid-thin1 ~/368/hw02
$ gcc stack.c test_stack.c stack_utils.c -o test_stackWriting the code
Follow the test-driven development process described above. We have made this easy for you by giving you a set of starter test cases (test_stack.c), as well as some utilities to help with testing (stack_utils.c and stack_utils.h).
-
Get
test_minimum_block_size_empty_stack()working. You will need to implement a little bit ofcreate_empty_stack(…). At this point, yourcreate_empty_stack(…)need only work for empty stack. For.num_values_per_node, just use 1. You can figure out the calculation of.num_values_per_nodelater. - Submit.
-
Get
test_minimum_block_size_1_value()working. This should require no changes tocreate_empty_stack(…). At this point, it only needs to work for stacks with one value, where eachBlockNodecan hold at most one value. This will require implementingpush(…)and one call tomalloc(…), but there will be no non-trivial calculations. You don't need to worry about adding additional nodes (beyond the first one), yet. - Submit.
-
Get
test_minimum_block_size_1_value_peek()working. You will simply implement thepeek_value_from_top_node(…)function. It returns the value of the top node in the conceptual stack. - Submit.
-
Get
test_32_bytes_per_block_node_empty_stack()working. Now you can figure out the calculations. At this point, all you need to do is havecreate_empty_stack(…)calculate the right value of.num_values_per_node, given themax_block_size_bytesgiven. Do not usesizeof(BlockNode),sizeof(Stack),sizeof(int), or any constants (except forNULLandMIN_NODE_BLOCK_SIZE_BYTES). Also, do not initialize (or otherwise set) the fields of theStackobject using->; use either designated initializer (See Q&A.) or compound literal (See Q&A.). - Submit.
-
Get
test_32_bytes_per_block_node_1_value()working. - Submit.
-
Get
test_32_bytes_per_block_node_3_values()working. - Submit.
-
Get
test_32_bytes_per_block_node_8_values()working. - Submit.
-
Get
test_32_bytes_per_block_node_12_values()working. - Submit.
How much work is this?
Relative to the provided skeleton (stack.c), the instructor's solution adds/modifies 31 source lines of code (SLOC), excluding assertions. This code follows all code quality standards and uses no advanced methods or C language features.
“Source lines of code (SLOC)” always excludes comment lines and blank lines.
👌 Okay to copy/adapt anything in this screenshot.
Requirements
- Your submission must contain each of the following files, as specified:
file contents stack.c functions create empty stack(size t max block size bytes)→ return type: StackCreate a new emptyStackstruct object.The
Stackstruct object is just a wrapper for the address of the topBlockNode, along with a field (.num_values_per_node) for the number of values to store in each block node. (See Q&A.)- The stack should be initially empty (i.e., no block nodes).
- ⚠ This returns a Stack object—not an address.
-
Hint: Since
create_empty_stack(…)returns aStackdirectly—and not an address of aStackobject—you know it must be on the stack segment (of memory) and not on the heap. (We usemalloc(…)to allocate memory on the heap.) Thus, there is no need to usemalloc(…)to allocate memory for theStackobject. Furthermore, since the stack is initially empty, there is no need to callmalloc(…)to allocate space for block nodes (since an empty stack needs no no block nodes).
is empty(Stack const✶ a stack)→ return type: bool- Return
trueif the stack is empty, orfalseif it contains any values.
push(Stack✶ a stack, int value)→ return type: void- If the top block node (
a_stack -> top) is full (i.e.,.num_empty_slots == 0), this should make room for the new value by adding a new block node.
pop(Stack✶ a stack)→ return type: int- Pop a value from the stack.
- If after popping a value from the array-based stack within the
block node, that block node becomes empty
(
.num_empty_slots == a_stack -> num_values_per_node), then this should pop aBlockNodefrom the block stack. Otherwise, no block nodes should be popped.
peek value from top node(Stack const✶ a stack)→ return type: int- Return the value at the top of the stack, without modifying the stack in any way.
empty(Stack✶ a stack)→ return type: void- Make the stack empty.
- After calling this function, the stack should be in the same state
it was right after calling
create_empty_stack(…). -
⚠
empty(…)may not callpop(…)
- Do not modify stack.h, stack_utils.c, or stack_utils.h.
- You should modify test_stack.c to ensure adequate testing.
- Caller is responsible for freeing memory allocated for the stack by either calling
empty(&stack)or popping every value usingpop(&stack). empty(…)may not callpop(…).-
Calculation of
.num_values_per_nodemust be dynamic. Do not attempt to hard-code values. - Use of
assert(condition)is strongly encouraged, but the condition must not have any side effects. (See Q&A.) - You must submit at least 6 times, with at least 10 minutes between each submission.
-
malloc(…)may only be called frompush(…) -
free(…)may only be called bypop(…)andempty(…). -
Your code must meet all code quality standards. For example:
- Do not use
sizeof(BlockNode)anywhere. - Do not use
sizeof(int)anywhere. - Do not use
… = (BlockNode*) malloc(…)anywhere. - Do not use
▒▒▒ -> ▒▒▒to initialize struct fields, unless you have articulated a reason why you cannot use a designated initializer or compound literal. - Declare variables where you initialize them, whenever possible. (See Q&A.)
- (See the code quality standards for more information about these, as well as additional rules.)
- Do not use
- ⚠ Do not use typecasts anywhere in HW02. The code quality standard says typecasts may not be used, except when they are truly necessary, safe, and you can articulate why. They are not necessary for anything in HW02.
-
Only the following external header files, functions, and symbols are allowed in stack.c.
All others are prohibited unless approved by the instructor. Feel free to ask if there is something you would like to use.header functions/symbols allowed in… stdbool.h bool,true,false*stdio.h *test_stack.cassert.h assert*stdlib.h free,EXIT_SUCCESStest_stack.cstdlib.h mallocstack.c -
Follow the policies (including the base requirements)
and academic integrity. For example:
- Do not copy code from generated by Chat-GPT (or other GenAI tools).
- Do not copy code found on the web.
Submit
To submit HW02 from within your hw02 directory,
type
368submit HW02 stack.c
Q&A
Do we need to check if
No. Although many C courses teach that, we do not require it because ① we are not covering good ways of handling run-time errors in this class; ② we have no easy way to force that error to happen in order to test if your error handling code works, and ③ it is extremely rare. (Prof. Quinn has never seenmalloc(…)returnedNULL?malloc(…)fail.)How can I use a designated initializer to initialize a struct object?
Example:
typedef struct Point { int x; int y; } Point make_point_on_stack(int x, int y) { Point new_point = { .x = x, .y = y }; return new_point; }
How can I use a compound literal to initialize and return a struct object in one step?
Example:
typedef struct Point { int x; int y; } Point make_point_on_stack(int x, int y) { return (Point) { .x = x, .y = y }; }
-
How can I use a compound literal to initialize a struct object on the heap?
Example:
typedef struct Point { int x; int y; } Point make_point_on_heap(int x, int y) { Point* a_new_point = malloc(sizeof(*a_new_point)); *a_new_point = (Point) { .x = x, .y = y }; return a_new_point; // caller is responsible for freeing }
-
What does it mean that an assert condition may have no side effects?
Example:- ✘
assert(pop(&a_stack) == 5)modifies the stack (bad). - ✔
assert(peek_value_from_top_node(&a_stack) == 5)examines the stack without modifying it (good).
- ✘
What is the purpose of the
Putting these in a single struct object makes your module easier to use. Someone using it does not need to know how it works internally. Moreover, if you make something like this and then decide later to change how it works internally (e.g., to use something other than a linked list), you can do so without having to modify the code that uses it.Stacktype? Why not just use the top of the stack to refer to the stack?How can I get the number of byte per value in
create_empty_stack(…)without usingsizeof(int)or hard coding (4)?Here is an ugly way that some people use to get the size of a struct type field when you don't have an object to refer to.
size_t num_bytes_per_value = sizeof(((struct BlockNode*)NULL) -> values[0]):
Here is another way that you might find more readable.
BlockNode dummy_block_node; // no need to initialize; we will not use this for anything size_t num_bytes_per_value = sizeof(dummy_block_node.values[0]);
👌 Okay to copy/adapt code from this Q&A item.
Updates
| 9/12/2023 |
|
| 9/13/2023 |
|