Image and Video Compression
Learning-based Image and Video Compression
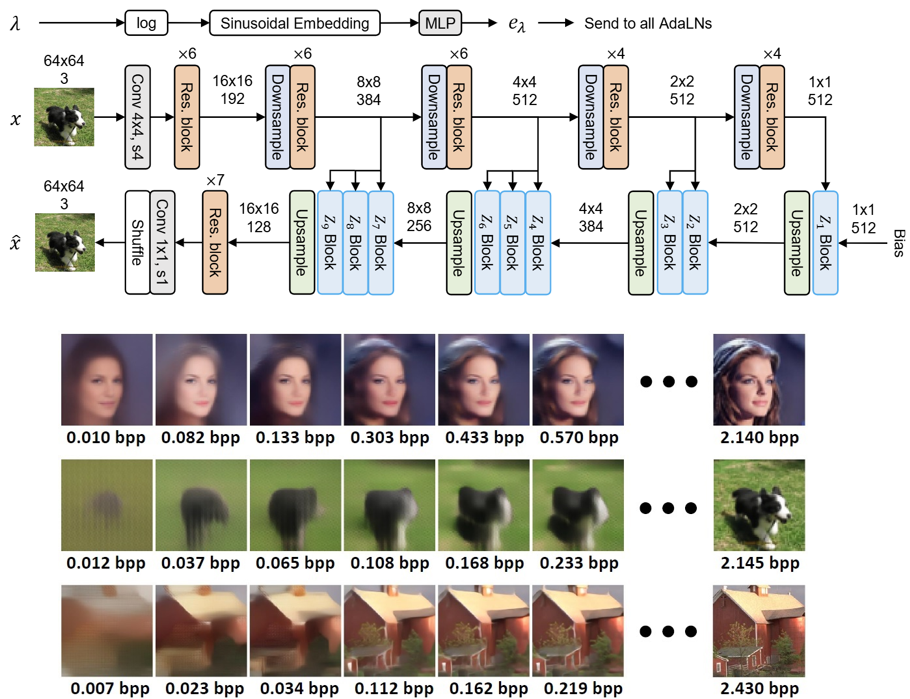 |
Data compression and generative modeling are two fundamentally related tasks. Intuitively, the essence of compression is to find all “patterns” in the data and assign fewer bits to more frequent patterns. To know exactly how frequent each pattern occurs, one would need a good probabilistic model of the data distribution, which coincides with the objective of (likelihood-based) generative modeling. Motivated by this, we study the problem of image and video compression from the perspective of probabilistic generative modeling. Publications:
|
Visual Coding for Machine Vision
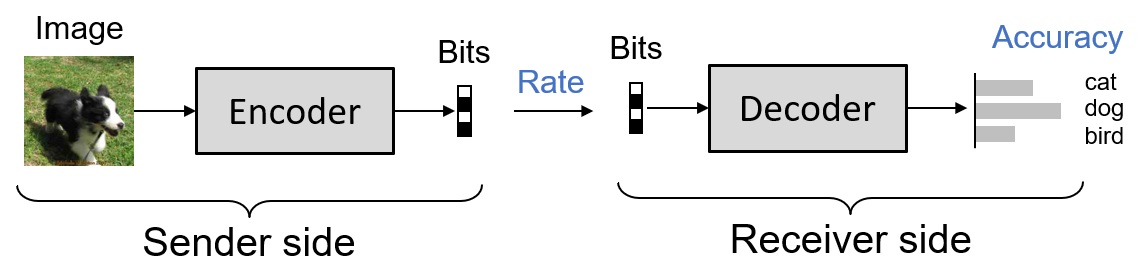 |
Visual data are traditionally designed to be viewed by human, and thus the compression techniques are also designed to reconstruct the original data. A recent paradigm, namely Coding for Machines, has been grown rapidly to embrace the era of AI and deep learning. In many modern applications that involves autonomous visual analysis, visual data needs to be compressed, stored/transmitted, but is then only processed by an AI algorithm (instead of human eyes) and is never reconstructed to the original form. Traditional methods that are mostly designed to reconstruct visual signal are thus inefficient in this new paradigm, and new techniques must be developed to account for new challenges and requirements. Publications:
|
Model Compression
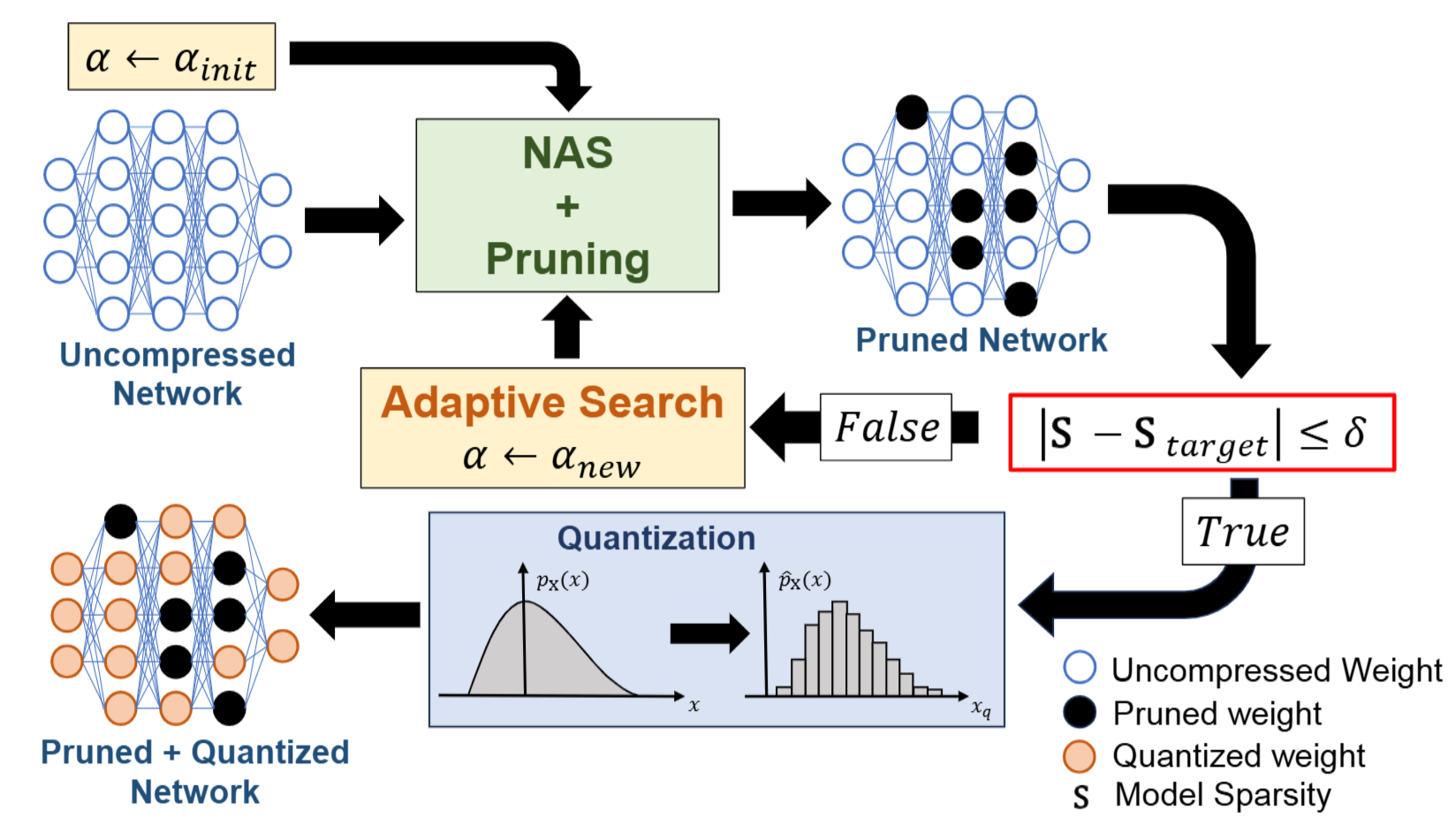 |
Deep learning models used in image compression often involve high computational complexity, making them challenging to deploy in resource-constrained environments. Model compression techniques, such as pruning and quantization, aim to reduce the size and computational cost of these models while preserving rate-distortion performance. Our research explores structured pruning and mixed-precision quantization methods specifically tailored for Learned Image Compression (LIC) models, enabling efficient deployment without sacrificing coding efficiency. Publications:
|
Deep Learning Based Pre-processing
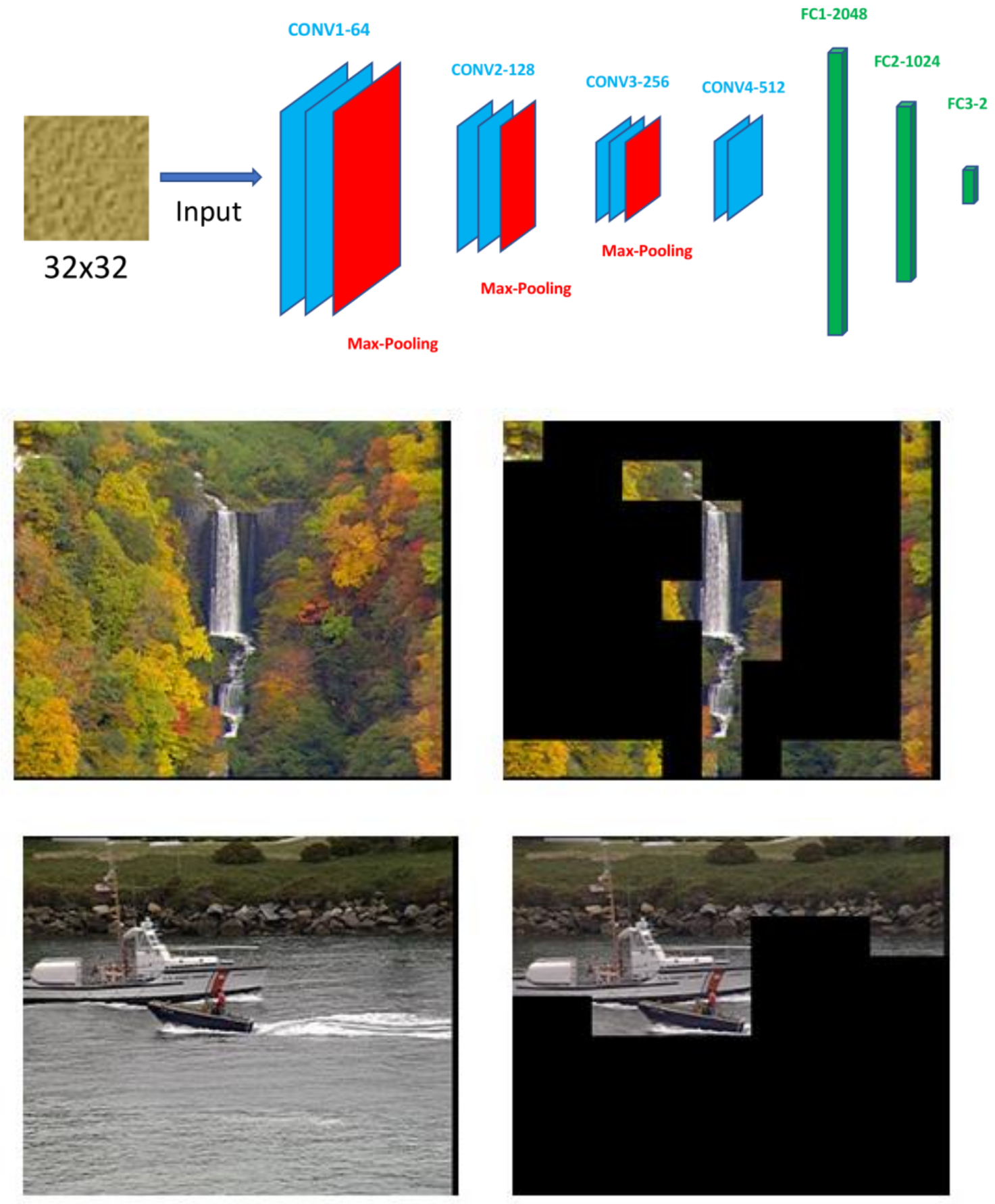 |
There has been a growing interest in using different approaches to improve the coding efficiency of modern video codec in recent years as demand for web-based video consumption increases. We propose a model-based approach that uses texture analysis/synthesis to reconstruct blocks in texture regions of a video to achieve potential coding gains using the AV1 codec developed by the Alliance for Open Media (AOM). The proposed method uses convolutional neural networks to extract texture regions in a frame, which are then reconstructed using a global motion model. Our preliminary results show an increase in coding efficiency while maintaining satisfactory visual quality. Publications:
|
Texture and Motion Based Video Coding
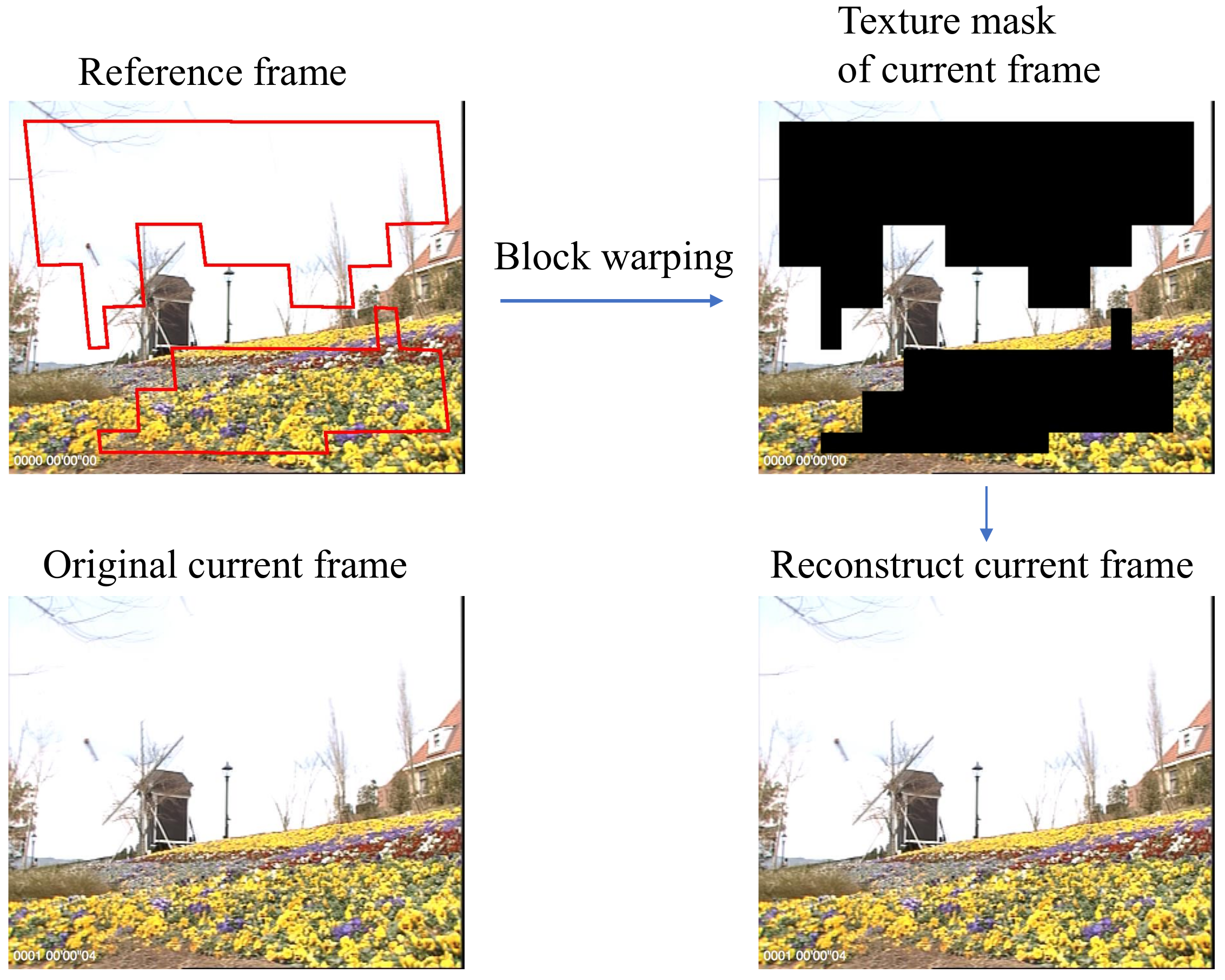 |
In recent years, there has been a growing interest in developing novel techniques for increasing the coding efficiency of video compression methods. One approach is to use texture and motion models of the content in a scene. Based on these models parts of the video frame are not coded or “skipped” by a classical motion compensated coder. The models are then used at the decoder to reconstruct the missing or skipped regions. We propose several spatial-texture models for video coding. We investigate several texture features in combination with two segmentation strategies in order to detect texture regions in a video sequence. These detected areas are not encoded using motion compensated coding. The model parameters are sent to the decoder as side information. After the decoding process, frame reconstruction is done by inserting the skipped texture areas into the decoded frames. Publications:
|