Real-time Multimedia Applications
Telepresence novel view synthesis
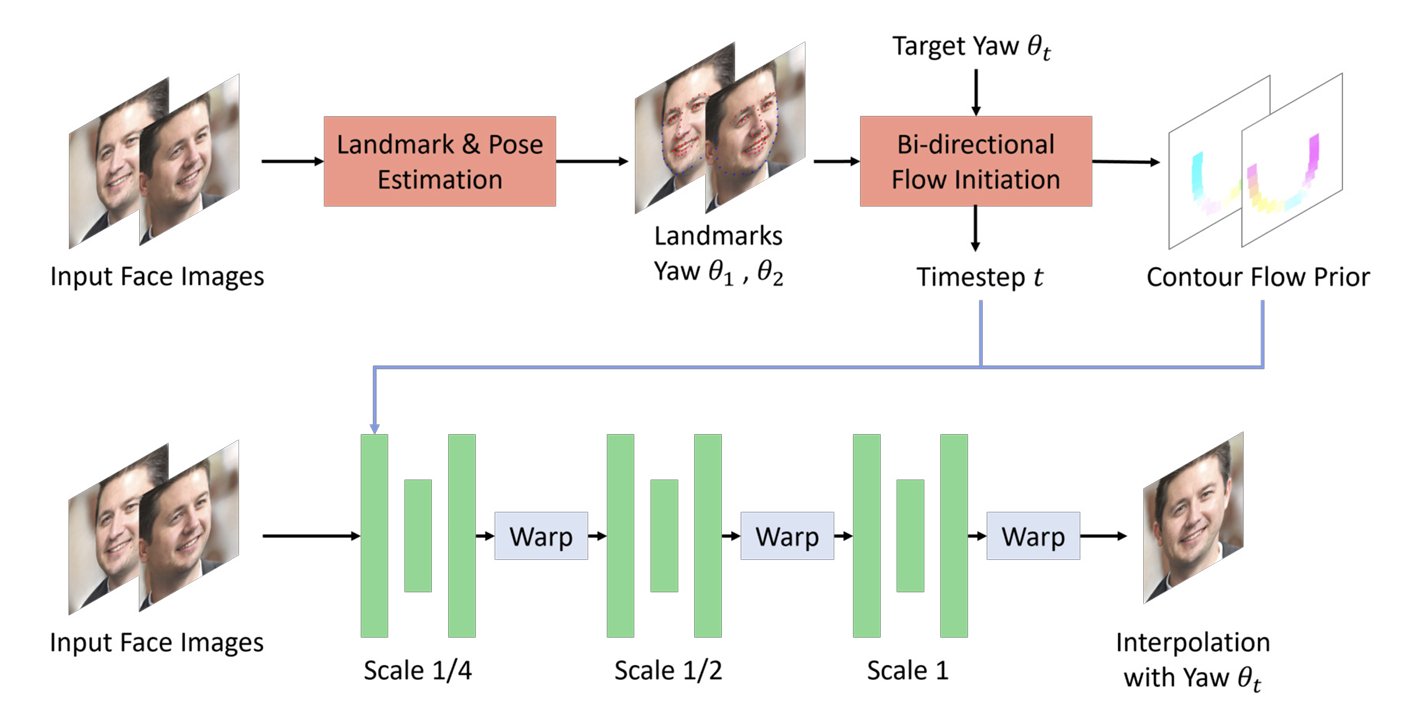 |
Video conferencing has become an essential part of remote work. However, traditional conferencing setups with a single webcam cannot achieve immersive experience due to lacking the visual cues that convey depth and perspective. To address exsiting challenges, we introduce a method that interpolates novel views from a pair of input views to achieve free view experience. Improvements are established around the view interpolation method to achieve high fedilty and temporal consistent novel views. Publications:
|
Real-time and Lightweight Video Portrait Segmentation
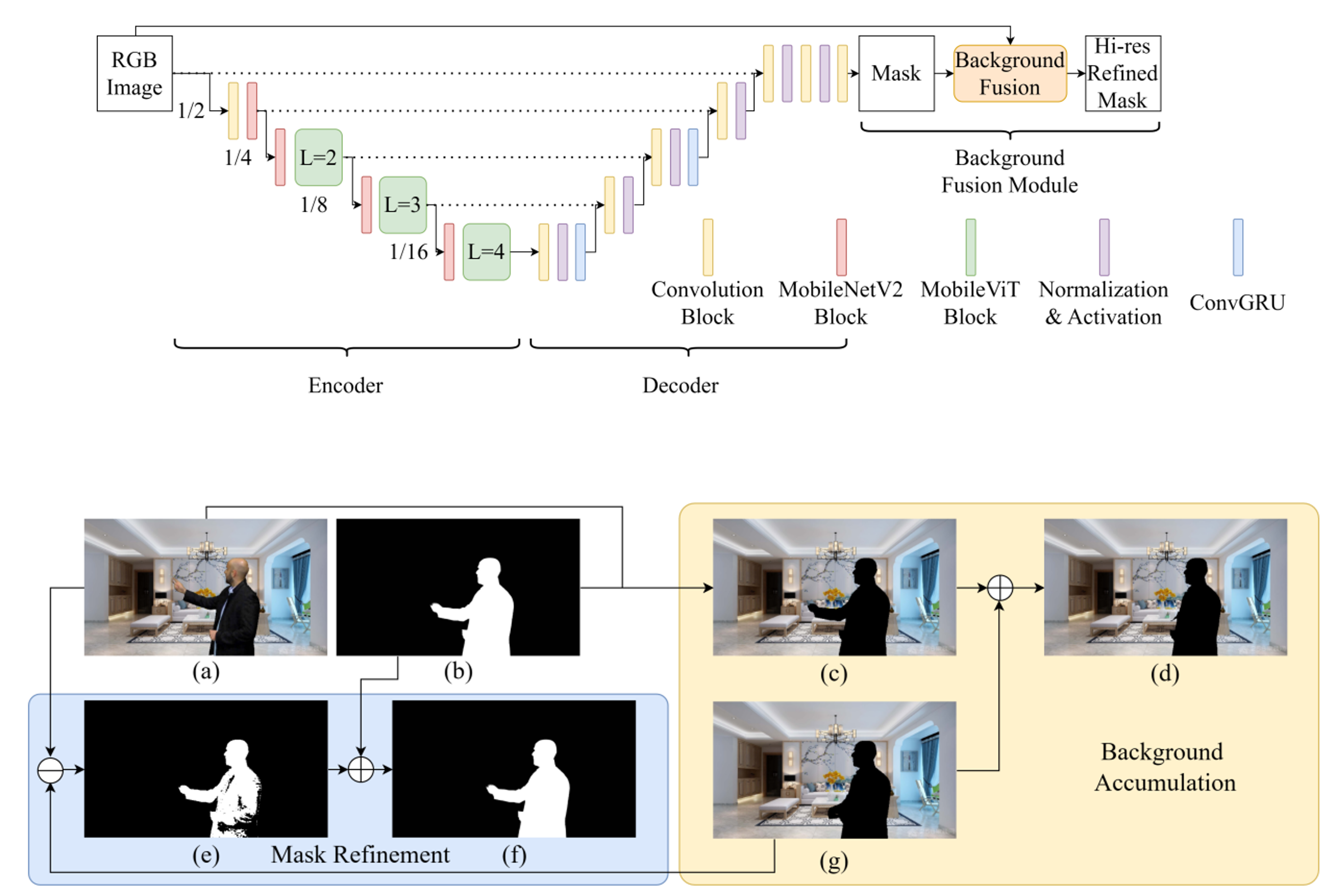 |
Video conferencing usage significantly increased during the pandemic period and is expected to keep popularity in the hybrid work. One of the key aspects of video conferencing experience is background blur and background replacement. In order to achieve a high-quality background blurring effect, accurate portrait segmentation and high-quality blurring effect are necessary. Existing methods have achieved high accuracy on portrait image segmentation, but valuable temporal information is often not fully leveraged. Motivated by this, our proposed method uses deep learning network combined with temporal information to perform high quality and consistent portrait video segmentation. Publications:
|
Video Desnosing and Super Resolution
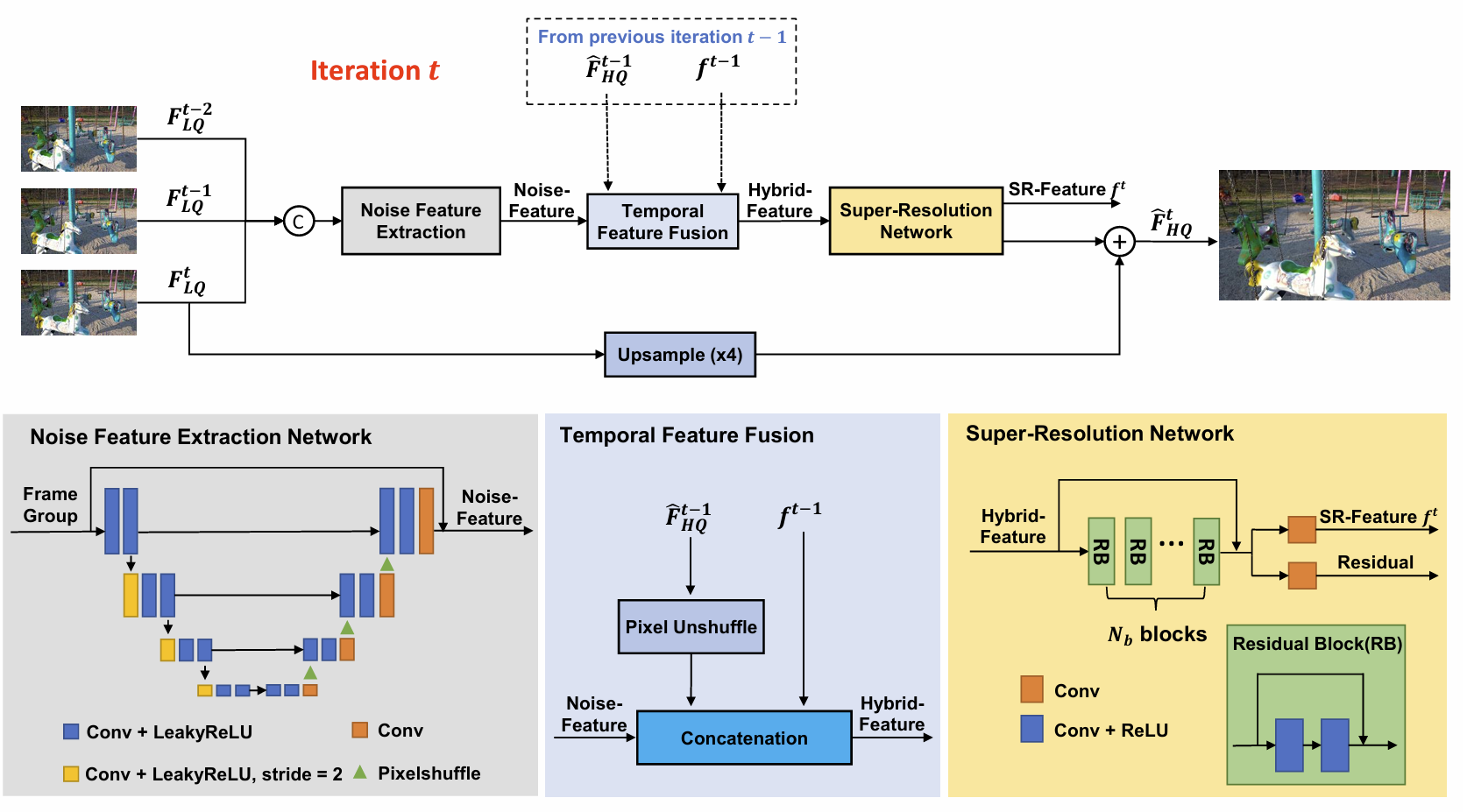 |
Denoising and super-resolution are two important tasks for video enhancement. In many real-world applications such as video conferencing, the input video obtained from a webcam or external camera is often noisy. Directly applying an SR network to noisy video will significantly undermine the performance of the SR and yield unwanted artifacts. There are very few works that target both tasks simultaneously, which motivates us to combine the two process into a joint architecture. Publications:
|
Virtual Reality Facial Expression Tracking
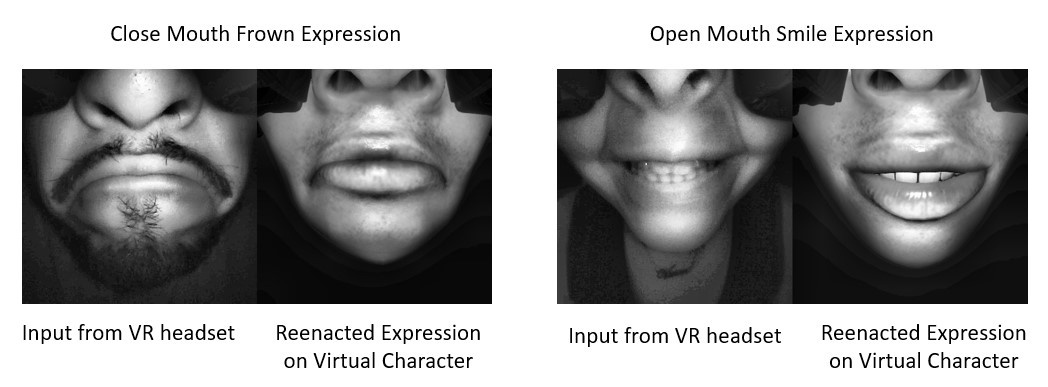 |
Headsets designed for Virtual Reality (VR), often referred to as Head Mounted Displays (HMDs), provide a significant means for individuals in the real world to engage with computer-generated virtual environments. One of the main challenges has been the manual annotation of real people facial expression parameters, known as Action Units. Synthetic data has therefore become a popular choice for model training. However, potential inaccuracies can arise due to discrepancies between the synthetic and real data distributions. Our research delves into this domain shift issue, bridging the gap between synthetic and real people data domains with domain adaptation methods. Publications:
|