



|
Maryam, Roberta, and Mike’s Funwork #3 |
|
WTA and Hopfield Networks |

|
WTA Algorithm |
|
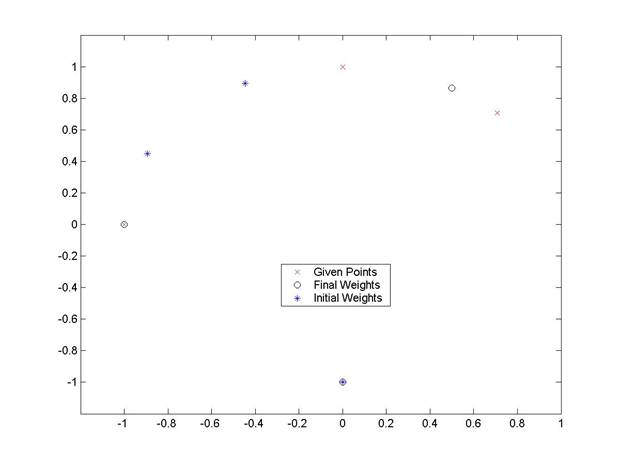
In this section, a Matlab m-file was developed to execute the Winner-Take-All (WTA) algorithm. The algorithm was designed to match the input points with the weight closest to them, and then adjust the weight using a gradient method to move the weight even closer to the input point. After many iterations, this algorithm positions the individual weights so that they are in the geometric center of the related group of inputs. The code for the algorithm is shown on the following page. Shown below is a sample execution of the program with the output plot. X is a matrix of column vectors, each of which defines the 2-dimensional points that are to be grouped. W is the initial weight matrix, which is also composed of column vectors that described points in the 2-dimensional space. Alpha is the parameter that governs how far along the gradient the weight vector will travel. The parameters returned by the function wta are the final set of weight vectors after the specified number of iterations, and a copy of the original input vectors. In addition, a plot of the initial and final weight vectors, along with the points specified in X, is created. >> x = [-1 0 1/sqrt(2); 0 1 1/sqrt(2)] x = -1.0000 0 0.7071 0 1.0000 0.7071 >> w = [0 -2/sqrt(5) -1/sqrt(5); -1 1/sqrt(5) 2/sqrt(5)] w = 0 -0.8944 -0.4472 -1.0000 0.4472 0.8944 >> alpha = 0.5; >> [wf,xf] = wta(alpha,x,w,200) wf = 0 -1.0000 0.5000 -1.0000 0.0000 0.8660 xf = -1.0000 0 0.7071 0 1.0000 0.7071 |
|
By changing the order of the input points, or rearranging the columns of X, different training sequences can be created. In this case, all of the points were entered in order (1,2,3), and it is clear that only 2 neuron’s moved during the course of the grouping. This implies that the third neuron is “dead”, or not affecting the system. The reason that this neuron is “dead” is because it starts out farther away from all of the input points, and so never gets an opportunity to move closer. On the other hand, all of the other weights continue to be updated, and so they continue to approach the input points nearest them. It is conceivable that varying the input sequence might affect the convergence of the weights, but in this case the “dead” neuron is simply too far away to get a chance to “win” in the algorithm. The only way to eliminate the dead neuron for this set of input points is to change the initial weight vector. By changing this vector, it is possible that each neuron will be drawn to only one point, rather than having one dead neuron and one neuron grouping two inputs. |
|
Figure 1. Plot of the positions of the initial weight vectors, the final weight vectors, and the input points. |