Please read this handout carefully before submitting the project. Contact the TAs if you have any questions about the project. Also please read the newsgroup constantly for any updates in the project handout.
Your task in this step is to generate a scanner (also referred as tokenizer) for the project's grammar provided to you. A scanner is a program that takes a sequence of characters (the source file of the program) and produces a sequence of tokens that will be used to feed the compiler's parser.
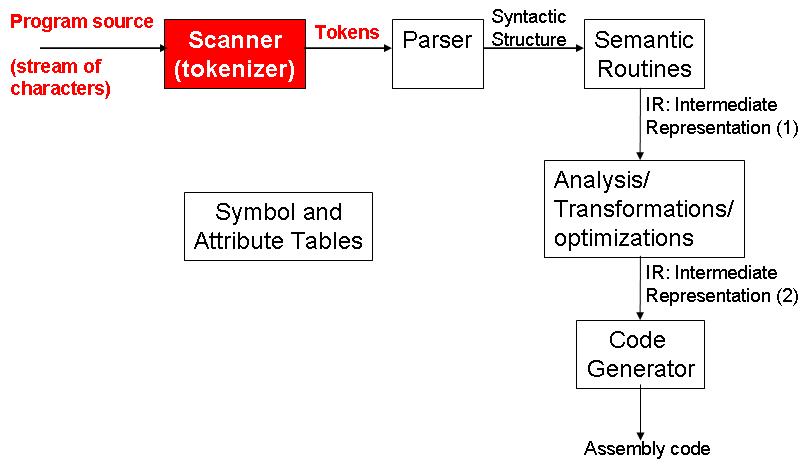
The figure below shows the general structure of a simple compiler similarly to the one presented in the Fischer & LeBlanc's book. The picture highlights the part of the compiler that will be developed at this step and conceptually relate it to other parts that will be developed in the future.
The scanner's source code is normally generated by a scanner generation tool. You can use one of the tools available to generate your scanner in this step. These tools normally work by taking the token definitions expressed by regular expressions and generates the source code for the scanner automatically (for this project, the tokens are specified in the language's grammar). The programmer has to add the code to handle the scanner's output. For example, at this step you will print all the tokens in the standard output. In the step 2 of this project you will modify your scanner to feed the parser replacing the print routines by calls to the parser and passing the tokens as parameters. In order to learn how to merge the code of the scanner generator with the rest of your source code, please, read the user's manual of the tool you decide to use.
Some popular tools are:
At the end of this step, the program developed (the very first part of our compiler) should be able to open a program's source file written in the LITTLE LANGUAGE and recognize its tokens. At this step, the output of your program should be the prints of each token's type and value (see below). In the next step the same output will be used to feed the parser.
Your scanner program should be able to open and read LITTLE source file and print the all the valid tokens within the source file and their respective type in the standard output. You might want to redirect the output to a file and compare your results with the output files provided for the testcases.
Testcases:
Outputs:
See grammar file for token definitions (Keywords, Operator, Literals)
The program is expected to print each token in a predefined format. Here is an example
Token Type: INTLITERAL Value: 20
Please read the output samples for more details.
This is how we will test your scanner in Java:
java -cp classes/:lib/antlr.jar Micro fibonacci.micro > fibonacci.scanner
This is how we will test your scanner in C/C++:
Micro fibonacci.micro > fibonacci.scanner
Note that the input is being read in from a file passed as a command line argument, not redirected from STDIN, while the output is being redirected from STDOUT. If you are using a different language that C/C++ or Java, include a shell script in your submission called "Micro" that provides the same usage interface as in the C/C++ case above
Note: This step will be graded automatically and the outputs generated by your code will be directly compared with the expected outputs using "diff -b -B" command. Please make sure the your outputs are identical to the sample outputs provided.
To help you start the project we are providing templates for step1. There is a template for ANTLR (v4) available. Because ANTLR v4 is new, the documentation is not as thorough as for v3. If you would like to use v3 for your project, there is an alternate template available.