Introduction
TORC, a tool for organizing referencing contents, is a Google Chrome extension designed to help users better organize and keep track of the texts they have read from different sources in a literature review setting. In the following sections we will demonstrate the system through a video and provide more details on the problem we set out to solve, the existing solutions, our design and implementation, our evaluation and our conclusion on the system.
Demo Video
Problem set out to solve
There exist many bibliographic tools today to help people store referencing materials for papers and reports and easily switch between different required formats. However these tools are usually not capable of helping users in determine which material to use or helping users in finding and organizing the actual content they wish to make reference to. Finding the right reference material in a literature review remains a tedious and time consuming process. What usually happens is a person has a vague idea on what information or data he or she might need. The person performs a search and finds a great amount of materials that might be somewhat relevant through to keywords searches. The person would read through most of them, selects a couple of source materials (such as technical papers) that are more relevant or reliable, and again study through these source materials to find the exact content (such as definitions or statistic results) the person wishes to reference.
However, by the time the user read through all the materials, he or she might not remember perfectly well what some of the previous materials are and have to go back and forth to find a better one to use. What’s even more troublesome is some of the source materials might have a few useful contents while not being a great overall source and it could be difficult to remember and find the exact content the user wishes to reference just by scanning through the source material again. This commonly practiced method is not only time consuming but also increases the chance of missing important contents in the process.
To address this problem we wish to provide a solution that in general will allow people to keep track and organize useful information from multiple sources for later usage. Our main application would be focusing on useful texts to be referenced during a literature review process, helping users better decide on which source material to reference and to relocate the actual referencing content from the source material more efficiently.
Existing solutions and other related work
By interviewing and observing a small amount of audiences from a research lab setting, we see a relatively common method of selecting references by first identify the potential source materials of known authors and through keyword searches. These graduate students usually scan through abstracts and graphics for a simple filter and keep track of the source materials they might find useful through saving, printing, or taking notes on the various systems such as Evernote. They then proceed to highlight specific texts that might be useful as they read through the source materials more carefully, whether it is on various software, or on printed copies. When finding specific contents they might reference later, we noticed some students simply underline the texts or circle the graphs while others might mark the importance / relevance with glyphs such as stars or exclamation marks. Most of the students that use glyphs would also mark the difference in its importance / relevance through the amount of repeated glyphs, the more glyph the more important / relevant the highlighted content is.
There also exist many tools that help users organize and manage their references such as the bibliography tool / function within Word or Latex or specific tools like EndNote or Zotero. Most bibliography tools store the different fields of information a citation would need and allow users to easily insert references and switch between different required citations formats but do not necessarily help users with reviewing the referencing materials. Specific tools like Zotero on the other hand do provide more help in this area. Tools like Zotero let users add annotations and tags to source materials allowing users to quickly find relevant referenced materials from the past. However these annotations might be influenced by the specific goal readers have in mind when storing the citation, and while tags help filtering unrelated papers it does not help users compare papers that share the same tags users are interested in.
Design
Our main design goal for the system is to help users better select source materials that are useful to them, and help them keep track and organize their references down to the actual content level rather than just the source material (the website or paper). We chose to implement the system in the form of a Google Chrome extension because we want the system to be something that can be easily installed and something users can directly interact with when examining the source materials. Google Chrome extension allows us to incorporate functions into the context menu (accessed through right clicks) instead of having users copy and paste the text and constantly switch between different tabs. Another reason we choose to use Google Chrome extension is because we do not wish to limit the system to only work for academia research papers, which would most likely be examined in some kind of PDF viewers, but we also want to welcome the possibility of referencing other web based resources. A Google Chrome browser allow users to examine both normal websites and PDF files, and therefore a Google Chrome extension that can directly interact with its opened tabs makes a perfect fit.
To help users more effectively locate the exact content they wish to use we decided to let users store/bookmark the actual texts within the source materials instead of only storing/bookmarking the source materials themselves. To make the system more learnable and memorable we would like it to be as close to users’ original methods as possible, therefore honoring the highlighting and the importance-making actions. We let users bookmark/store the referencing contents by highlighting the actual text, and save it through interacting with the right-click context menu. We then let users annotate the about-to-be-stored referencing text on its importance and its category. We also store information on the actual source material the contents are from, so when users need to decide on which source material to use they can get automatic suggestions on better fitting source materials. We propose two methods on suggesting source materials. Method one suggests materials with a higher average importance rating on its referencing contents and method two categorizes referencing contents by categories and then orders each referencing contents by its rating to help users identify the most appropriate reference for a specific need more efficiently. For example if users need a convincing statistic reference they can chose to organize stored contents based on categories then all the referencing content that was categorized as Statistics will be grouped and sorted by their ratings, allowing users to quickly find statistics they marked “better” to use, instead of identifying a generally good source material and hoping the statistic it uses is just as good.
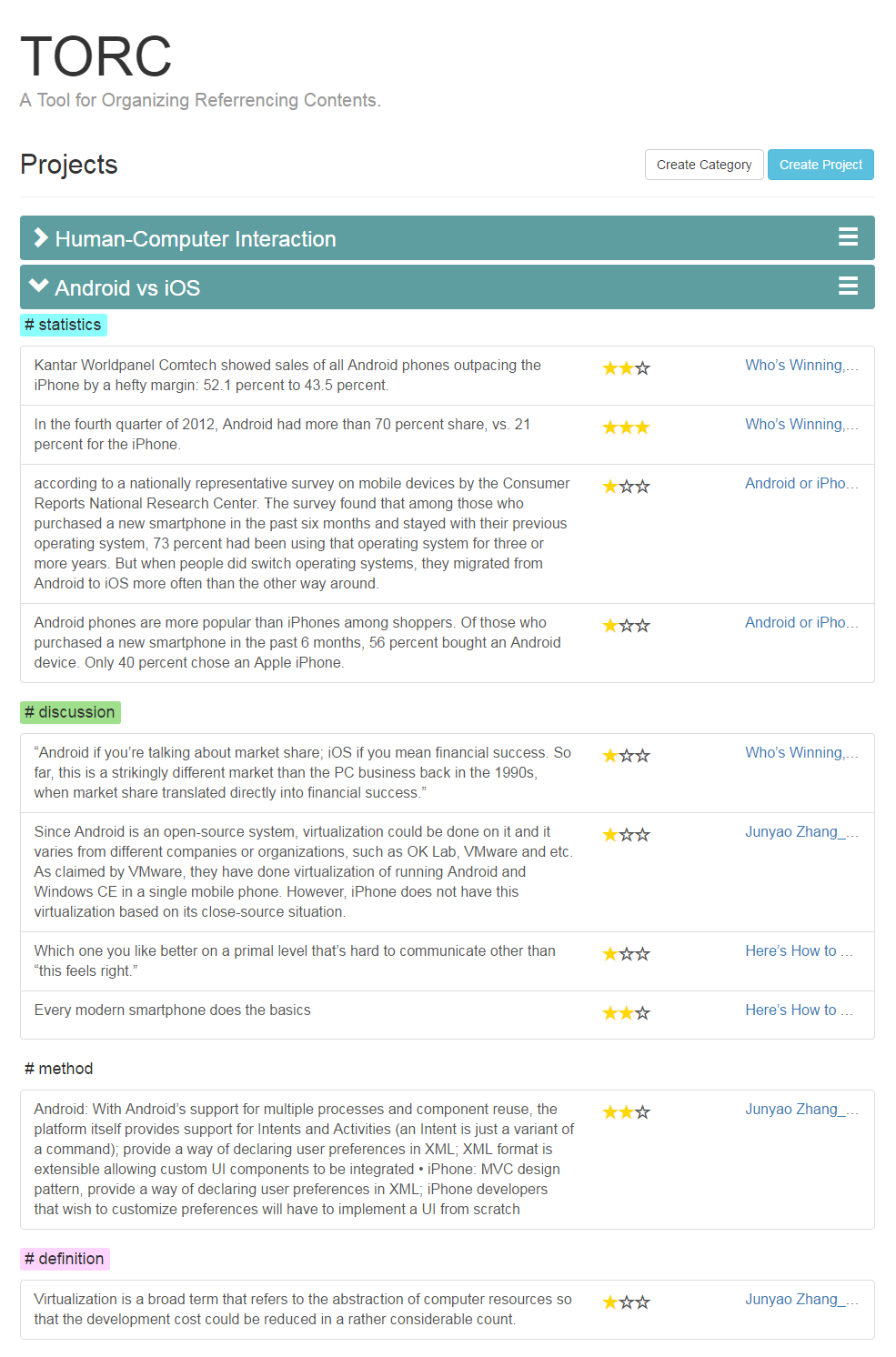
To help users create a better contextual model we also display references in the homepage in hierarchical structures with project/topic on the top level, source material or category on the second level, and the actual referencing content with its rating on the third level.
Implementation
To implement our framework with Google Chrome extension, the system can be broken down into three main components – the homepage, the popup, and the dialog. The popup (Fig. 1) allows users to see the references saved in the currently opened tab and provides a link to the homepage. The dialog allows users to annotate the details of each highlighted text and store it (Fig. 2). And the homepage allows users to organize, to quickly examine and to access stored referencing contents (Fig. 3). In the background of the system a server created through node js is being used to store website information, referencing contents, and corresponding annotations. We chose to store information through a server rather than Google Chrome’s local storage to enable users to synchronize between different devices. This however does mean until we create login accounts for different users, everyone using our Google Chrome extension would be sharing their collected references.
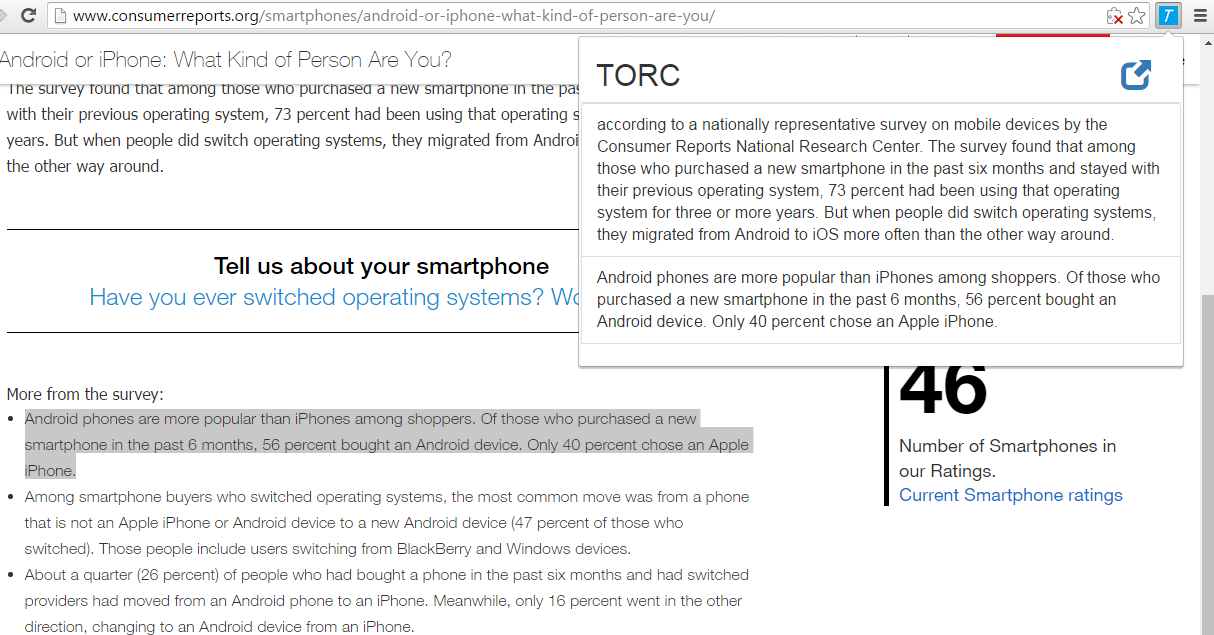
While examining a page, JavaScript functions in the background (written in background.js), through functions provided by Google Chrome API, will collect information on the tabs opened such as the tab’s title, url address, and the selected text. The Google Chrome API also provide functions to retrieve these information when PDF files are opened through the default Chrome PDF plugin, allowing users to highlight and store contents from both normal webpages and PDF files. Through normal JavaScript functions (written in content.js) the system can also retrieve the y-location of the highlighted text in the tab allowing users to jump to the exact location of referencing contents from the homepage and potentially highlight the stored text automatically (which is currently a work in progress). The y-location and auto-highlight functions, however, are limited to websites only and do not function in the PDF viewer plugin.
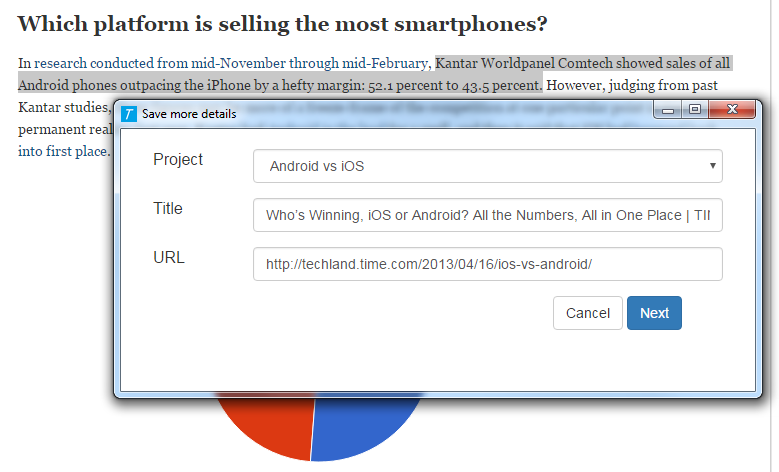
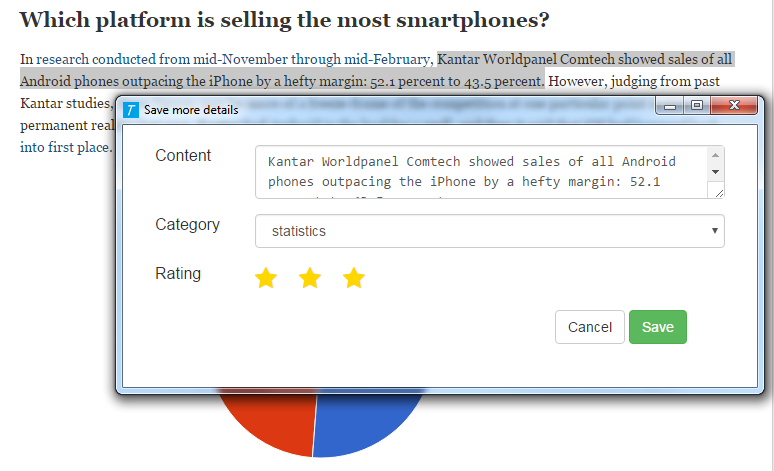
Once highlighted a text to save, users can right click and select the extension menu to store the highlighted text (note that the system currently does not support storing graphs, charts, images, videos or anything that is not text based). The system will first communicate with the server to see if the currently opened website has already been saved and opened up a dialog box (written in dialog.js). If the current tab has not yet been save, the dialog box will ask users to place the tab under a user-defined project (that was pre-defined in the homepage), and allow users to edit the title or the url of the tab. If the tab has already been saved for another referencing content the system will skip this dialog and go straight to the next dialog which asks users to select the category the content falls under, rate the content, and annotate the reference. After the referencing content is stored, it will be displayed in the homepage, which can be opened through the popup of the Chrome extension icon (written in popup.js). The homepage communicates with the server to retrieve all the stored data and display them in the method users select. Users can also edit their annotations in the homepage which will then be stored back into the server.
Evaluation
Due to the limited time, we decided to evaluate the system by interviewing and observing individuals on their experiences using the system. After a brief introduction on the system we ask users to pick a topic to perform a quick literature review on. Users will create a new project in the homepage for their research topic, find a few source materials that include at least 1 online article and 1 PDF file, save at least 2 contents from each source material, and in the end provide the content he or she would like to reference for the topic. We roughly time the process, observe users from behind, and ask users to evaluate the system with the 5 facets of usability, rating each facet from 1 to 5 with 5 being very satisfied and 1 being very unsatisfied after finishing the evaluation.
Again due to the time constraint and the main focusing use case we only selected participants from graduate students who are at least somewhat experienced in doing research and performing literature review.
Results
In the limited time we asked four graduate students from the course to perform the evaluation by using the system to do a simple literature review on their project topic. The feedback is mostly positive. Most students believe the Google Chrome extension can simplify their task and help them save time. One student praised the idea for being simple but effective. Another student expressed the concern on the process of right clicking and annotating the text will break up the flow of reading and distract the user, but still agreed the final result to be useful. And the results on the learnability survey after the evaluation are the following:
- Learnability: (5 + 4 + 4+ 5) / 4 = 4.5
- Efficiency: (4 + 3 + 3 + 4) / 4 = 3.5
- Memorability: (4.5 + 4 + 4 + 5) / 4 = 4.4
- Error-proneness: (3 + 4 + 4 + 5) / 4 = 4.0
- Satisfaction: (3.5 + 4 + 4 + 5) / 4 = 4.1
- Finish time: < 10 minutes
Conclusions
We created a system in the form of Google Chrome extension to help users organize possible referencing materials down to the actual content (text) level and better evaluate each potential source material for references. The system can be broken down into three main components:
- A homepage that displays all the saved contents, its sources, its rating and the project it is under. Users can organize and display the stored content in different orders to better identify referencing materials that are more effective.
- A dialog box that allows users to annotate highlighted texts and store them as potential future references.
- A popup that displays the highlighted text in the currently opened tab and links users to the homepage.
We evaluate the system by observing graduate students using the system, and received an overall positive review on the idea and the system. However with the amount of users tested and the method of the evaluation we are not able to provide a convincing usability result. If possible in the future, we would like to set up user accounts and logins to enable personal usage, incorporate image referencing into the system, and extend the evaluation for more casual users to better understand the effectiveness of our system.
Acknowledgements
We are really grateful because we managed to complete our TORC project with the guidance of Prof. Quinn. We also wish to thank everyone who spent time on the evaluation process. Without their valuable comments and feedback, we would have not been able to complete the system.