Multiple view action recognition is a logical next step to fixed-view action recognition because it addresses a more realistic scenario: it does not assume that humans are performing the action in a specific direction relative to the camera, e.g. frontal or profile views. In addition, capturing an action from multiple views obtains additional features of the action, thereby potentially increasing the discriminative power of the recognition algorithm.

Distributed and Lightweight Multi-Camera
Human Activity Classification
Human Activity Classification

Multi-camera algorithms generally involve some local processing specific to each camera and then the individual results from the cameras are aggregated to give the final classification output. Practical implementation of such algorithms on a distributed camera network places constraints on memory requirements, communication bandwidth, speed etc. This page outlines an algorithm that can potentially be implemented on a distributed wireless camera network and provides some level of invariance to the actor orientation and the camera viewpoint.

Figure 1. Few examples of multi-camera action sequences (bending, boxing, hand-clapping, running). Different camera images are scaled differently so that the subjects have approximately the same height in each view.
We propose a multi-view algorithm suitable for a distributed camera network. The action representation is based on histograms of spatio-temporal features extracted from multiple view video sequences of an action. The proposed system achieves invariance to orientation or the viewing direction of the actor. In other words, the actor is not restricted to a fixed orientation while performing actions. Rather she can have one of the multiple orientations and the number of such orientations depend on the number of cameras used in the setup. We use 6 cameras for training and testing in our experiments. Their spatial configuration is as shown in Figure 2.
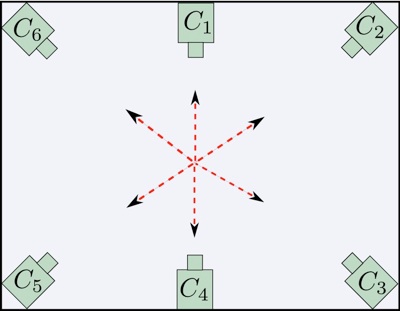
Figure 2. Camera spatial configuration.
The camera positions satisfy the assumption that we make in order to accomplish orientation invariance. The assumption is that since our algorithm uses spatio-temporal features extracted from the multi-camera image sequence, we can expect the set of features taken in their entirety from the 6 cameras to be substantially independent of the subject’s viewing direction while performing any action . From the subject’s viewpoint, she should see the same spatial configuration of cameras irrespective of the direction she is facing. This is illustrated in Figure 3 (a) and (b).
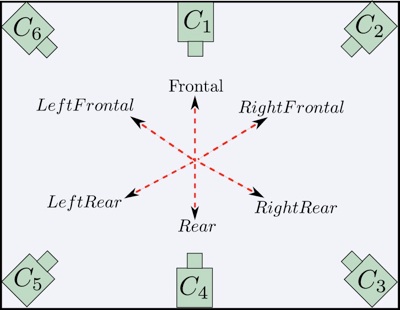

Figure 3. How orientation invariance is achieved using multiple cameras?
Figure 4 shows the conceptual schematic of a distributed processing architecture on which the action classification algorithm can be implemented. The current generation wireless cameras like WiCa and Imote2 are some examples of the camera platforms on which the algorithm can potentially be implemented. The cameras C1 − C6 act as image acquisition modules, each of which is associated with a processing module that executes the steps of the algorithm that are relevant to individual cameras. The processing modules can communicate with each other to exchange the test action’s histograms and can transmit the final distance values to the aggregation module. It is emphasized that entire images need not be transmitted from the processing modules to the aggregation module, as is the case with other recognition algorithms that rely on fully centralized processing of multi-view image sequences.
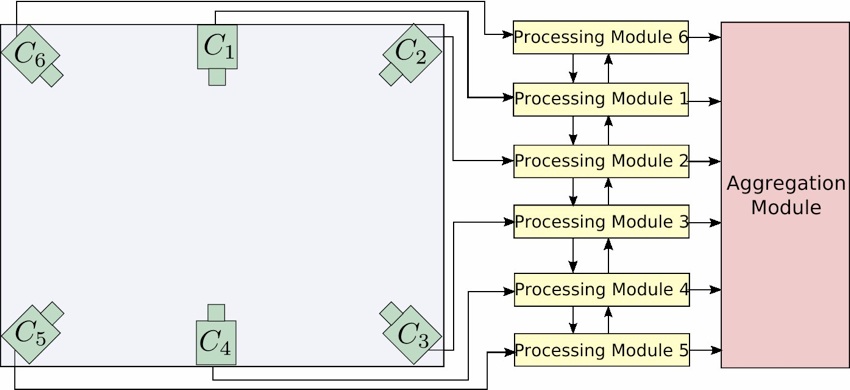
Figure 4. Conceptual distributed processing architecture for implementing the multi-view action classification algorithm.
If you are interested in the data set used in this project, please click here.

● Gaurav Srivastava
● Johnny Park
● Hidekazu Iwaki

Gaurav Srivastava, Hidekazu Iwaki, Akio Kosaka, Johnny Park, and Avinash Kak, “Distributed and Lightweight Multi-camera Human
Activity Classification” Third ACM/IEEE Conference on Distributed Smart Camera 2009 (Oral). [pdf] [slides]

• Tracking Humans with a wired Camera Network
