Computer Vision for Recognition of American Sign Language
This project offers a novel approach to the problem of automatic recognition, and eventually translation, of American Sign Language (ASL). We propose to take advantage of the fact that signs are composed of four components (handshape, location, orientation, and movement), in much the same way that words are composed of consonants and vowels. Instead of attempting sign recognition as a process whereby a match must be made between the analyzed input and a member of a stored set of lexical signs, we will treat sign recognition as the end result of several separate but interrelated component recognition procedures, of which the current project period concentrates on handshape identification.
To accomplish our goals, several areas of basic research are uniquely integrated by our project team: linguistic research on the structure of signs in ASL, psycholinguistic research on human perception of ASL, and advanced techniques from statistical pattern recognition and computer vision. This integration represents an advancement over previous approaches to handshape recognition or movement tracking. Here, we show some preliminary results for the movement tracking and handshape recognition.


Motion Segmentation under Varying Illumination
Extracting moving objects from their background or partitioning them have been one of the most prerequisite tasks for various computer vision applications such as gesture recognition, surveillance, tracking, human machine interface, etc. Though many previous approaches have been working in a certain level, still they are not robust under various unexpected situation such as large illumination changes. To solve this problem, we have worked with a motion segmentation based on the robust optical flow estimation technique under varying illumination. Following figures show the superior results of our motion segmentation method under varying illumination (click images to play movie clips).

Figure 1. Test image sequence for motion segmentation

Figure 2. Optical flow and motion segmentation results
Handshape Reconstruction
To reconstruct handshape from a stereo pair of handshape images, we calculate the disparity of image pixels first. The disparity represents the depth information between the object and two cameras as defined in figure 3. We calculate the disparities of image pixels in the stereo pair of images based on the Marr-Grimson-Poggio (MPG) algorithm. This algorithm employs a hierarchical approach using different level of edge images obtained by the Laplacian of a Gaussian (Log) operation and zero-crossing with different parameters. At the higher level of edge images, coarse but more reliable edges are obtained. The disparity of pixels calculated on the higher level of edge images is used at the lower level of edge images to get finer disparity of pixels. After the processing of nose removal, the disparity data are fitted to a surface using a spline curve fitting algorithm. A reconstructed hand surface is shown in figure 4. We are currently working on extracting important image features from the 3d range data of the hand surface to identify a specific handshape.
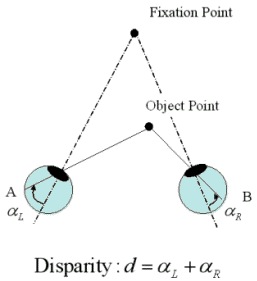
Figure 3. The disparity

Figure 4. A Reconstructed Hand Surface
Face Tracking for ASL Recognition
In one aspect of the ASL interpretation, the information from the signer's face is also important. For instance, the relative position between signer's face and hand is a part of the meaning of a sign and also is helpful to parse a string of signs. Furthermore, the facial expression of signers is also meaningful. For example, if the eyebrow is raised then the sentence should be interpreted as the "question" statement, otherwise it should be a plain statement. Therefore, in addition to analyzing the handshape in images, tracking the face is necessary for the complete ASL recognition system. Here, we present some results from our "very preliminary" face tracker. The tracking algorithm is based on a prestigious appearance technique called "Active Appearance Models (AAM)". The movie files below show the tracking results for the face and facial feature where the distances between the eyes to eyebrows are also measured. (click images to play movie clips)


Figure 5. Face Tracking Results
In the figure below, we show the plot of the eye-to-eyebrow distances versus the time (frame number) of the female signer sequence. We also show some face actions (e.g. eyebrow raise, change of orientation) with respect to the measured values. In future work, we will develop an algorithm that can automatically recognize these face expressions.
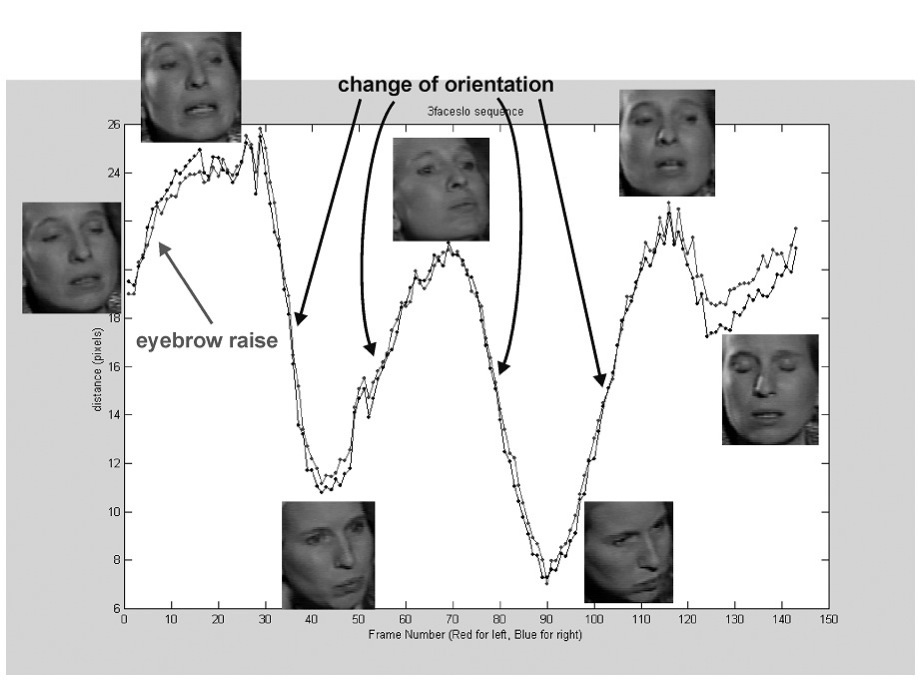
Figure 6. Eye-to-eyebrow Distances

• Yeonho Kim
• Akio Kosaka
• Pradit Mittrapiyanuruk

Yeon-Ho Kim, Aleix M. Martinez and Avi C. Kak, "Robust Motion Estimation under Varying Illumination", Image and Vision Computing, vol. 23, no. 4, pp. 365-375, 2005. [pdf, 0.8MB]
Yeon-Ho Kim, Aleix M. Martinez and Avi C. Kak, "A Local Approach for Robust Optical Flow Estimation under Varying Illumination", British Machine Vision Conference 2004, London, September, 2004. [pdf, 0.2MB]
A. M. Martinez, P. Mittrapiyanuruk and A. C. Kak, "On Combining Graph-Partitioning with Non-Parametric Clustering for Image Segmentation," Computer Vision and Image Understanding, Vol. 95, No. 1, pp. 72-85, 2004. [pdf, 0.9MB]

