Week 7:
Total: 8 Hours
Cumulative: 8 + 42.75 = 50.75
Show me a thing: My progress on reading in the input file and getting started in C
Entry 4:
Date: 10/7/24
Time: 8:15 PM
Duration: 2 Hours 45 Mins
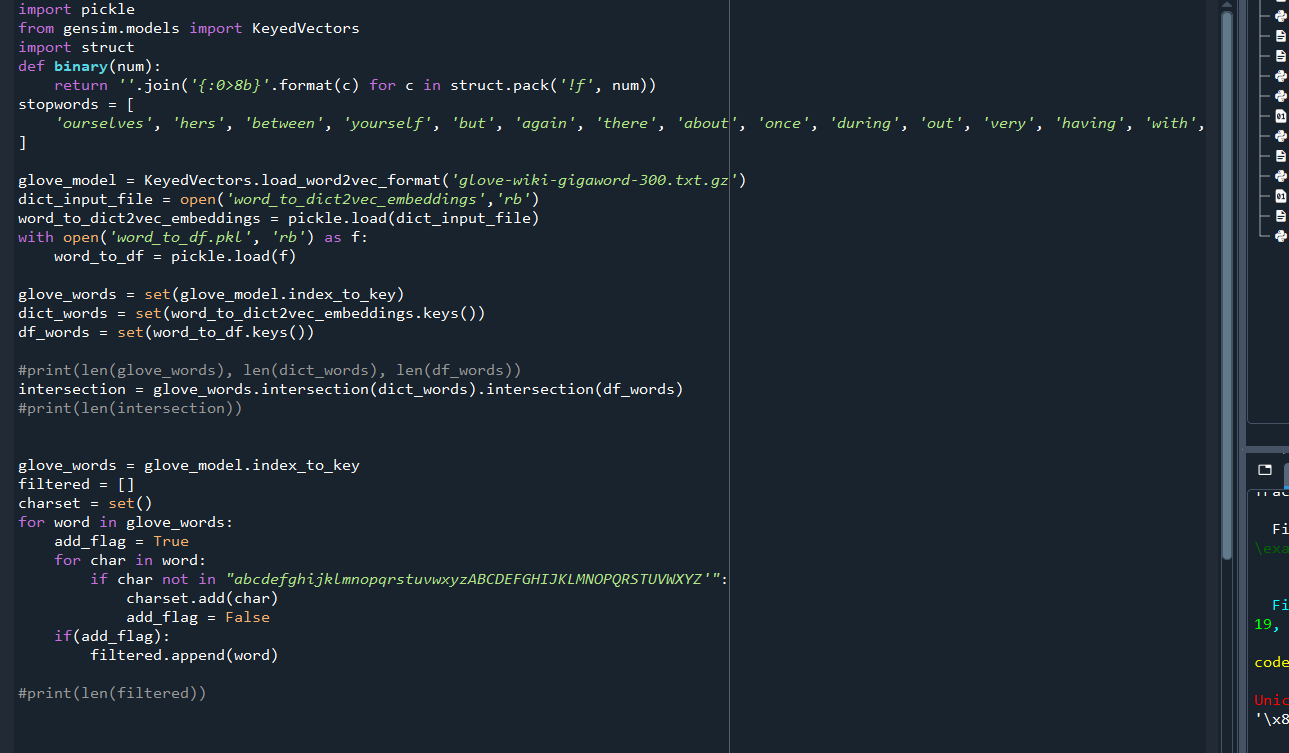
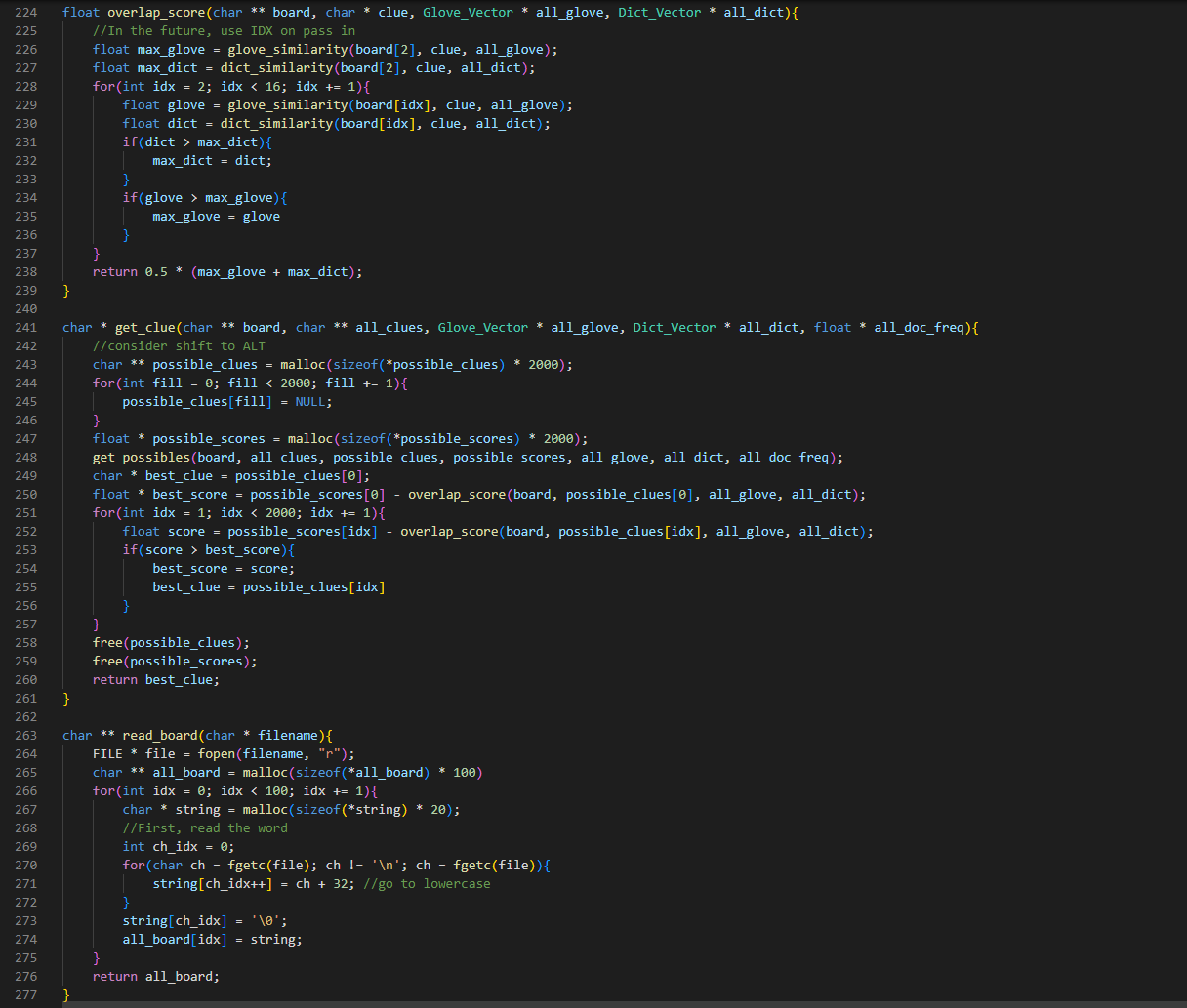
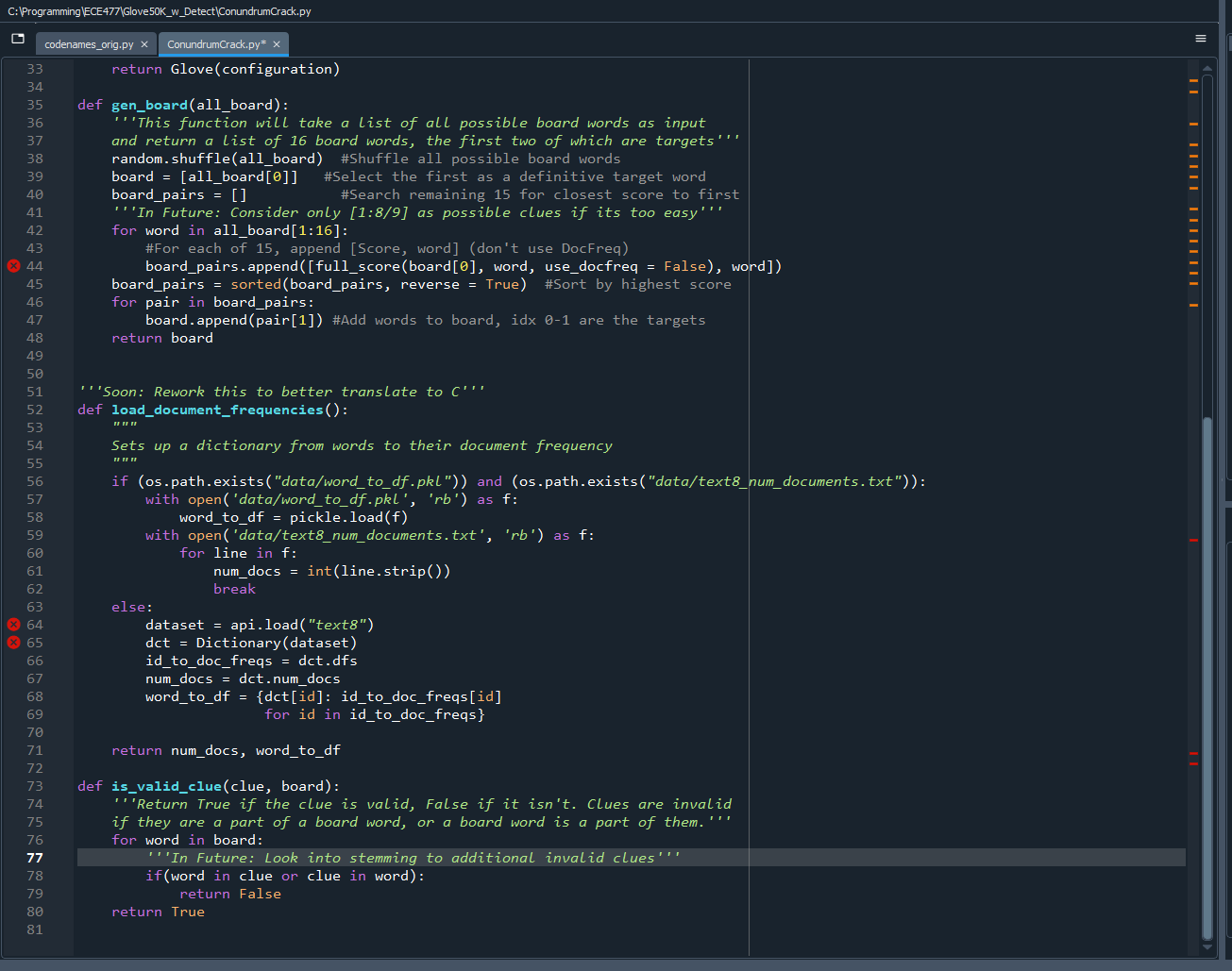
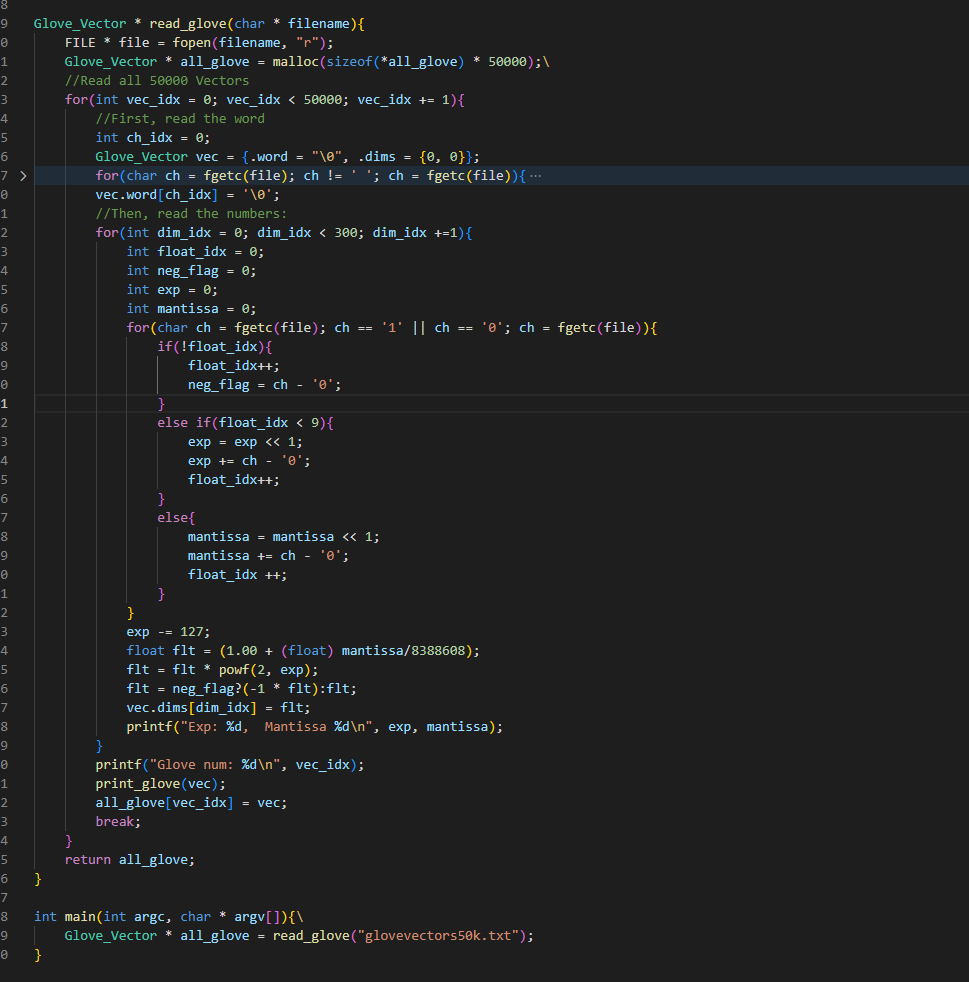
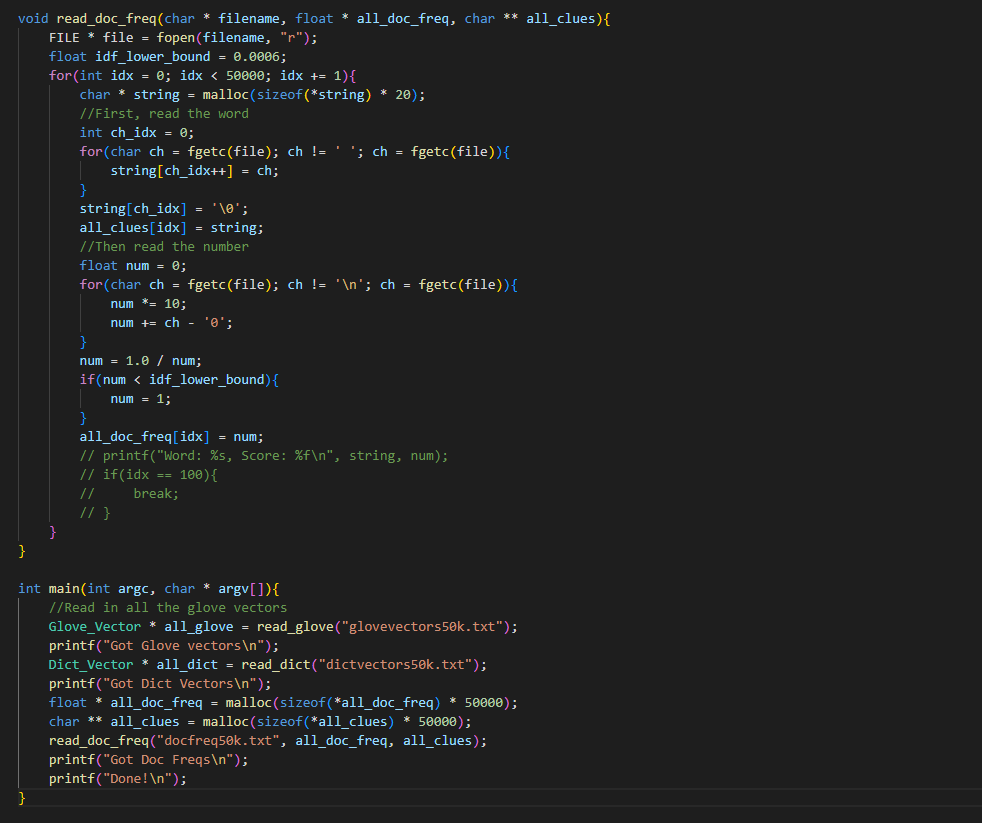
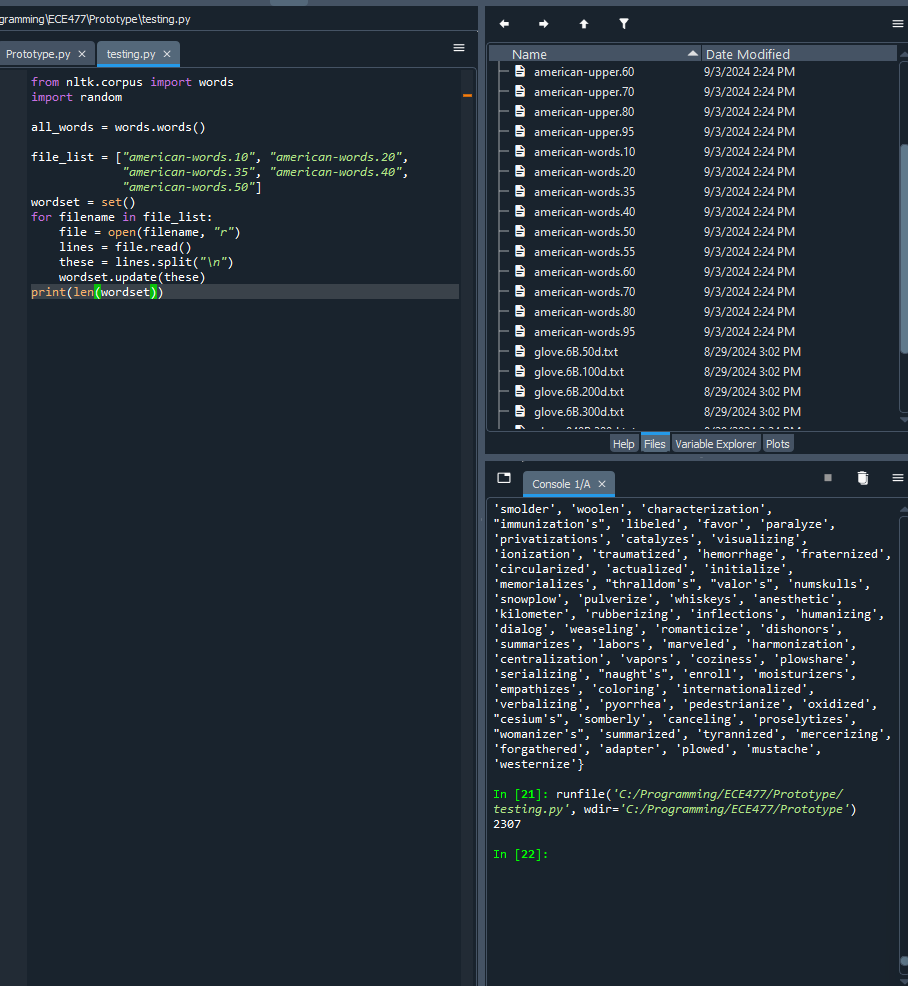
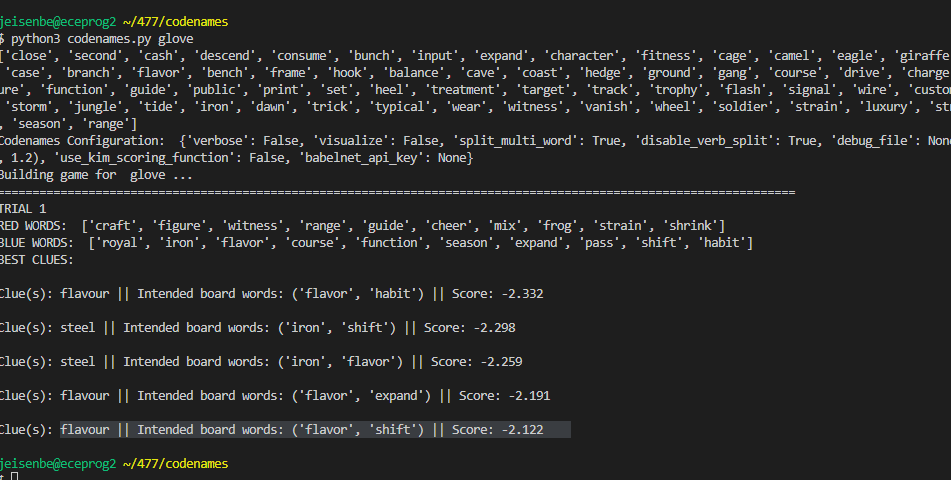
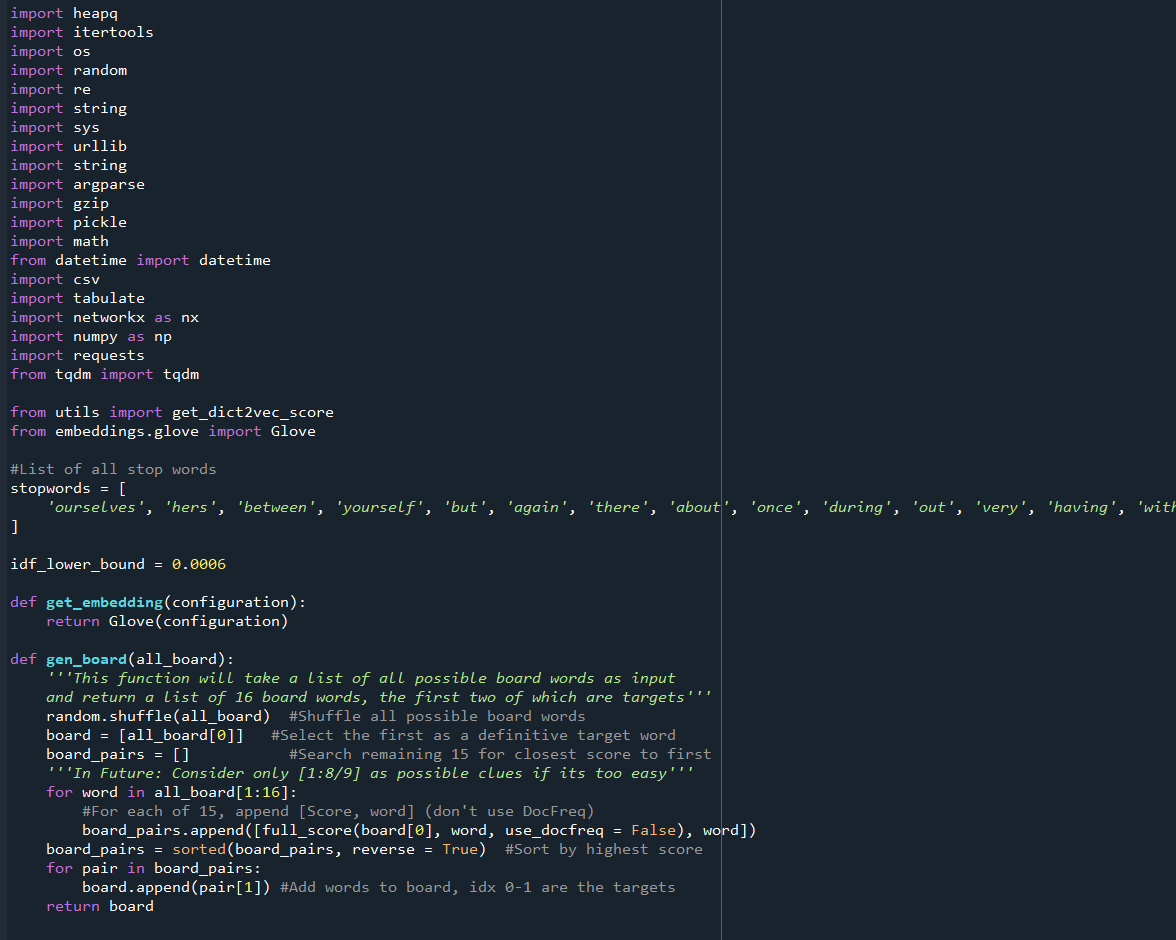
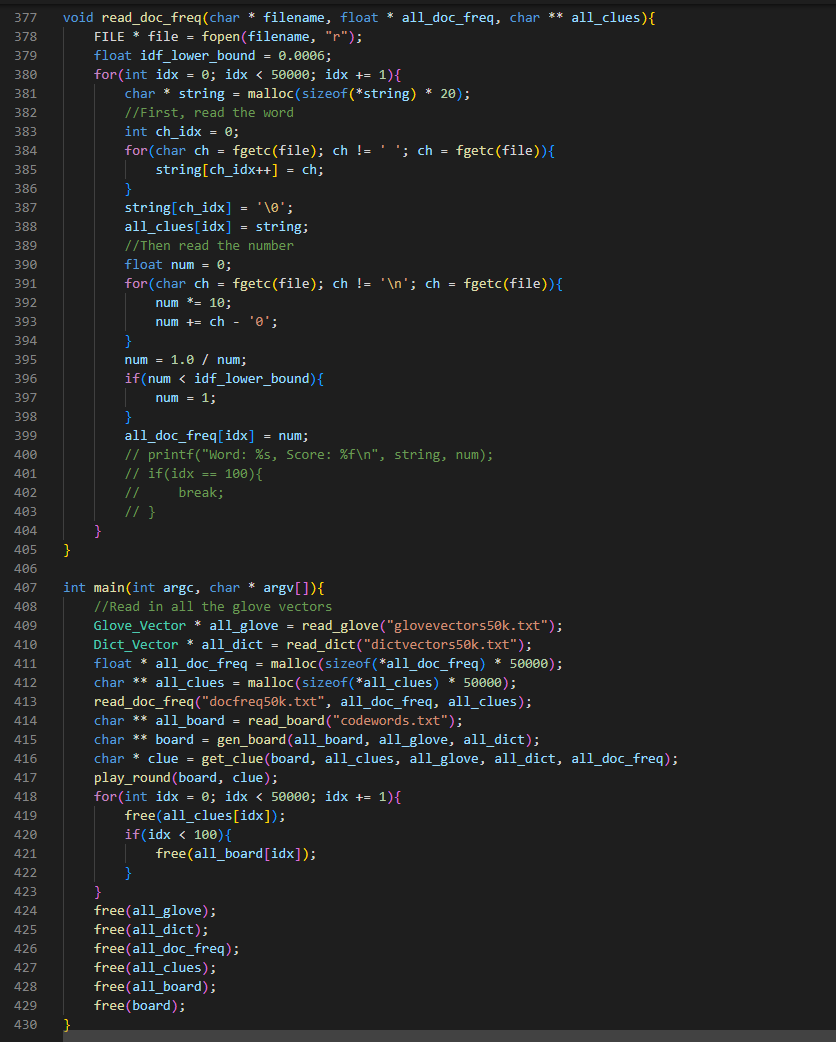
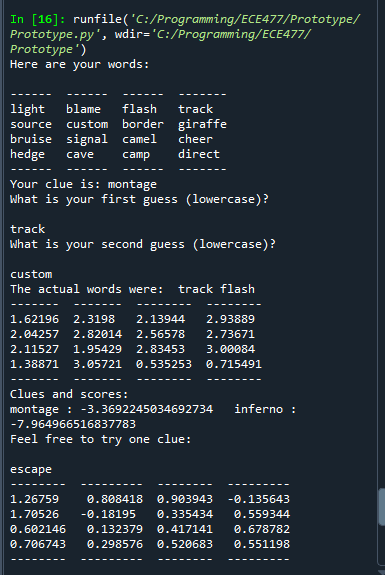
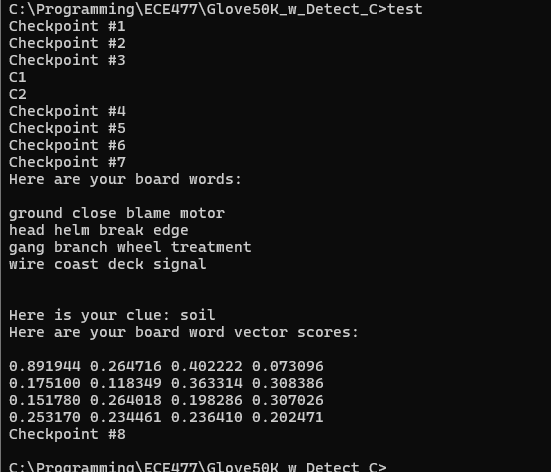
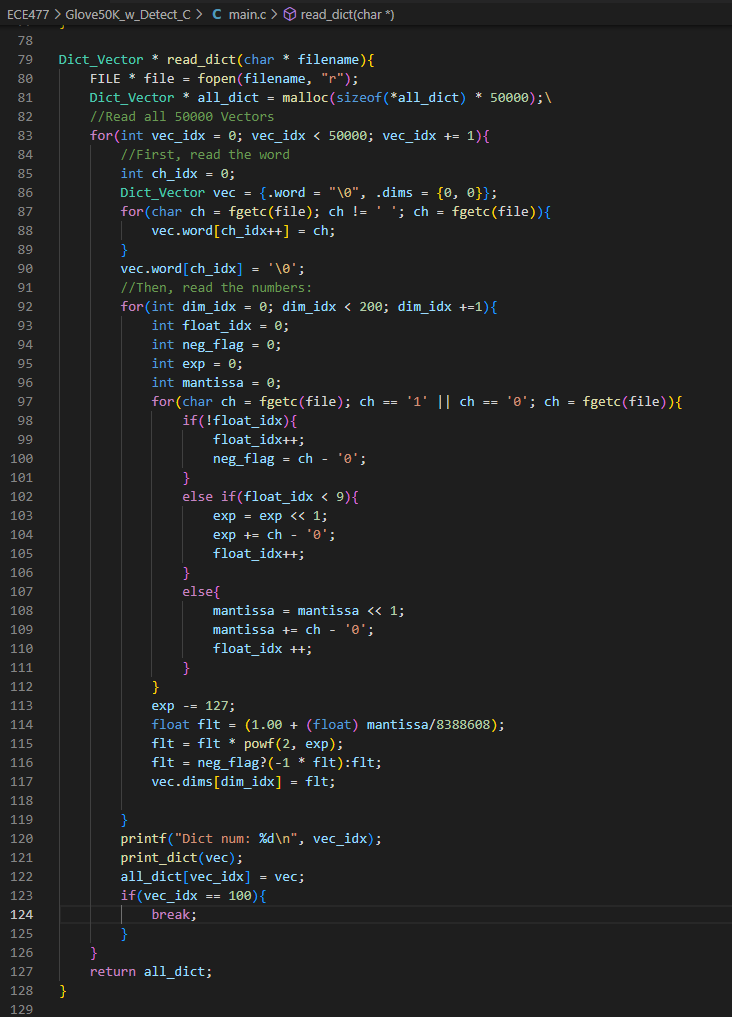
Worked on writing my code in c (mostly translating from python with some extra work):
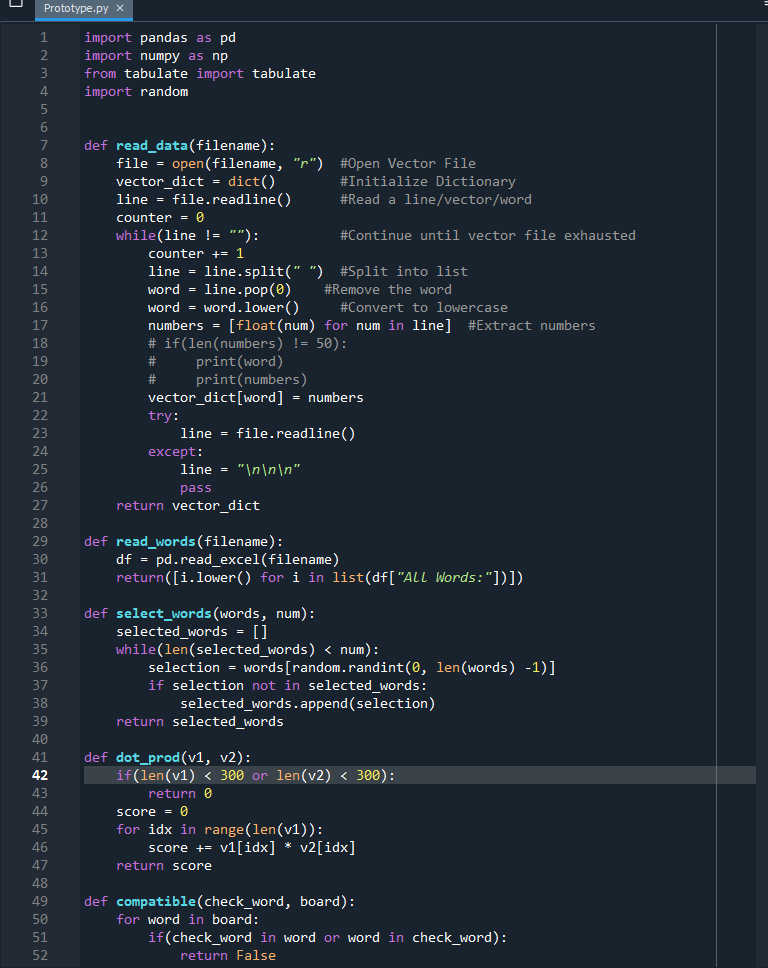
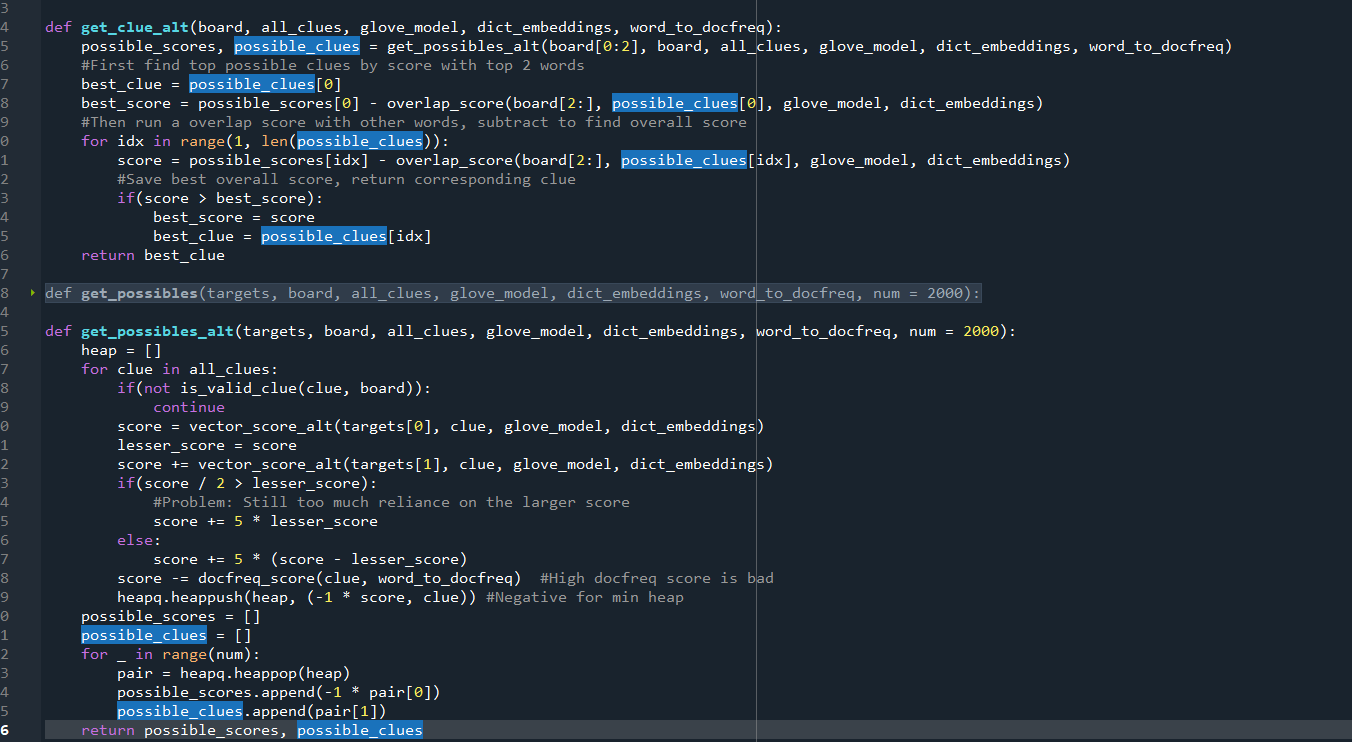
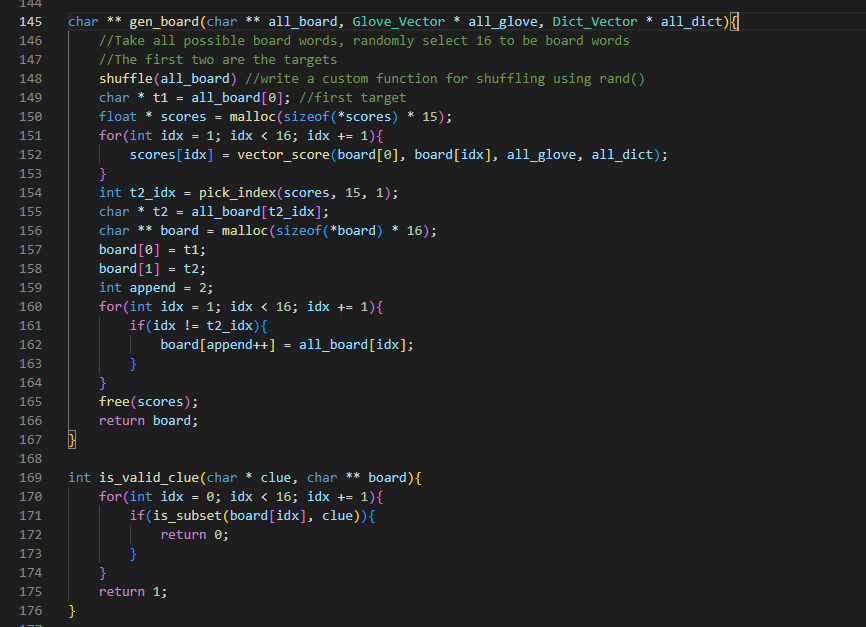
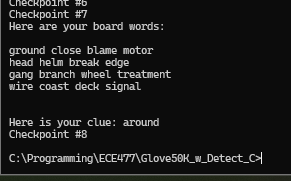
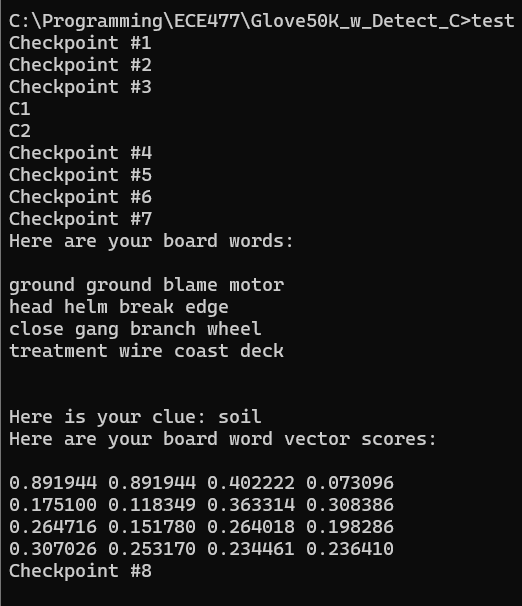
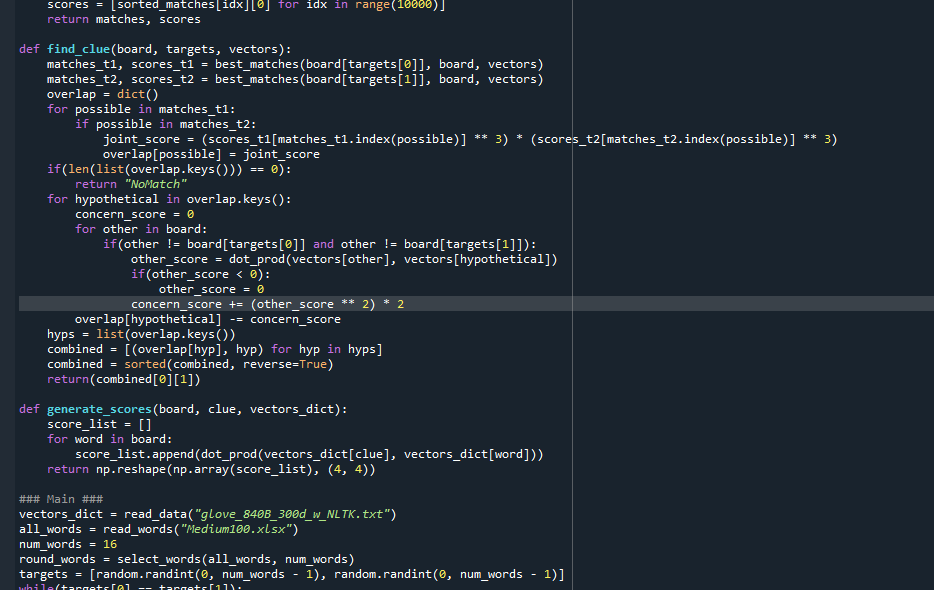
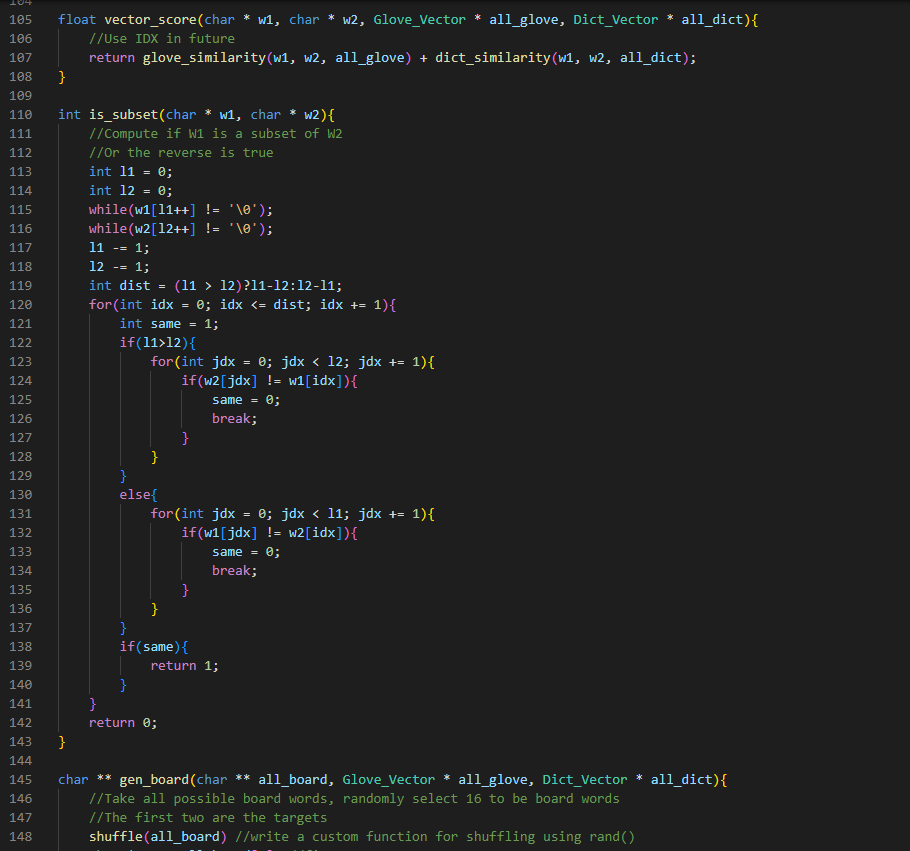
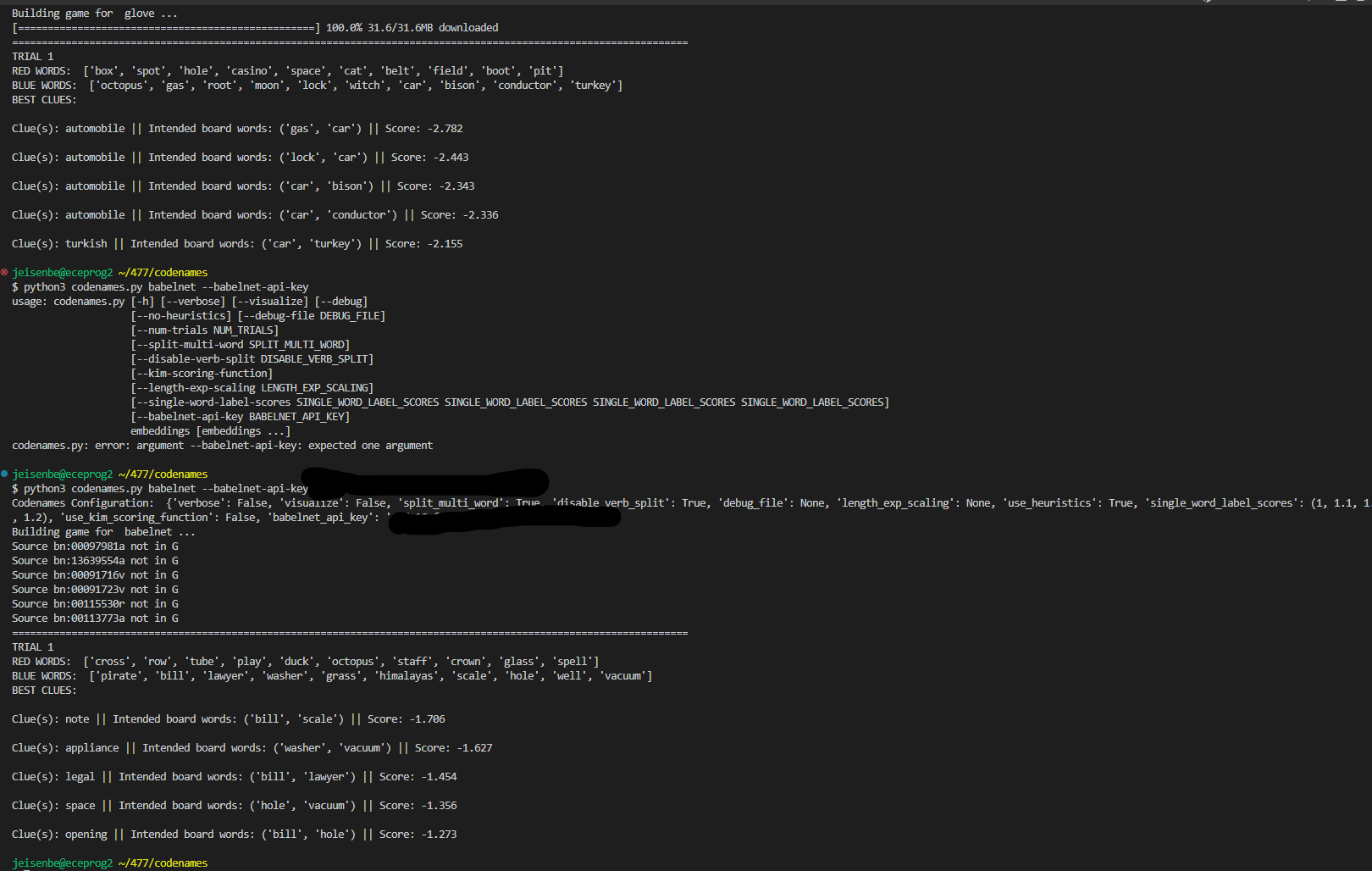
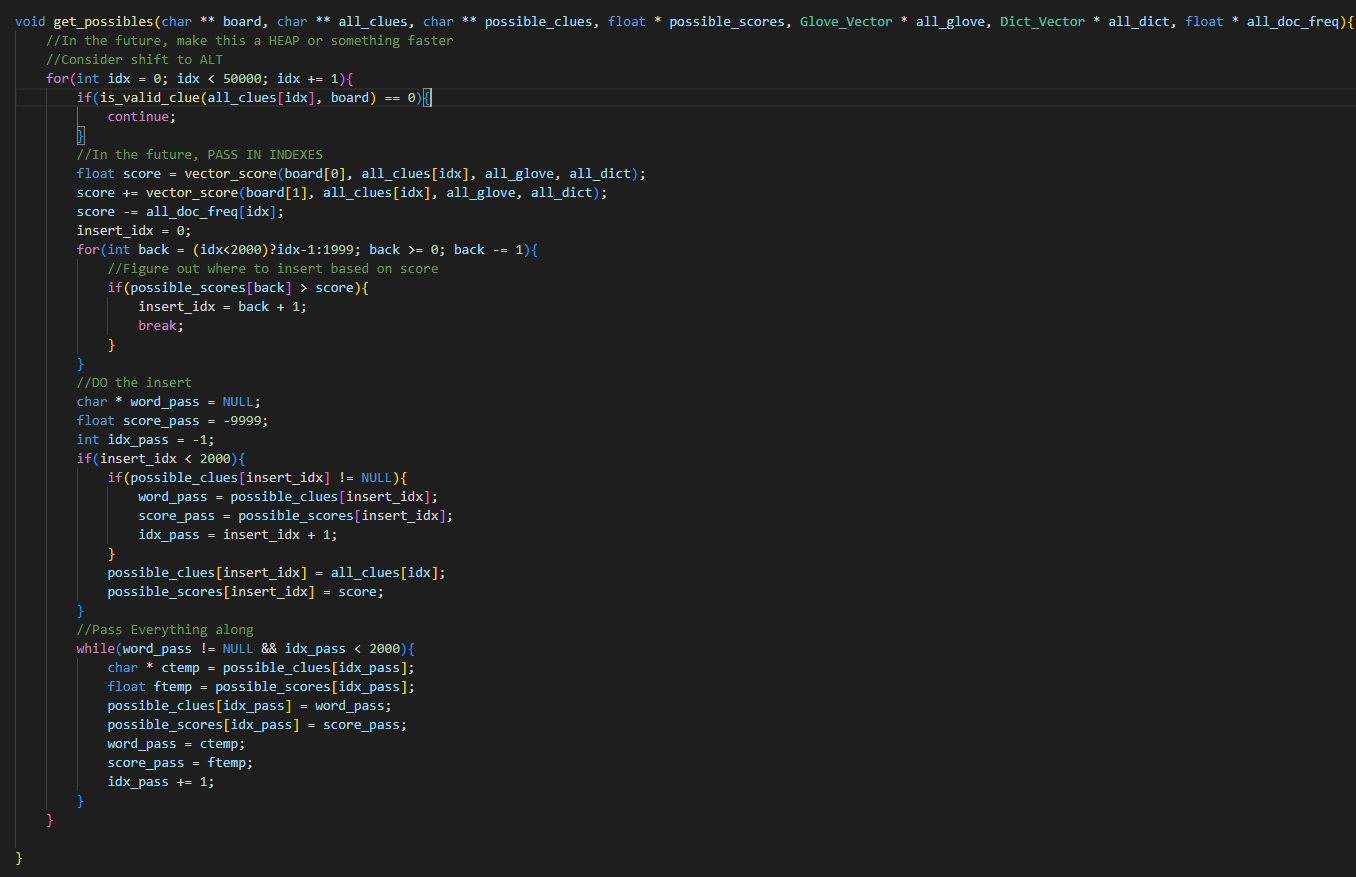
Here’s the current state of the code. It still needs testing, debugging, and needs to be made much more efficient, primarily by using heaps for get_possible, and passing in vector indexes (no long searches) for all of the cosine similarity calculations.
It’s not done and could get much longer, but this is actually shorter than expected.
(Reference: Used this: https://stackoverflow.com/questions/30404099/right-way-to-compute-cosine-similarity-between-two-arrays)
Also updating the website
To do in future: Debug and test, improve efficiency
Entry 3:
Date: 10/7/24
Time: 2:15 PM
Duration: 2 Hours 45 Mins
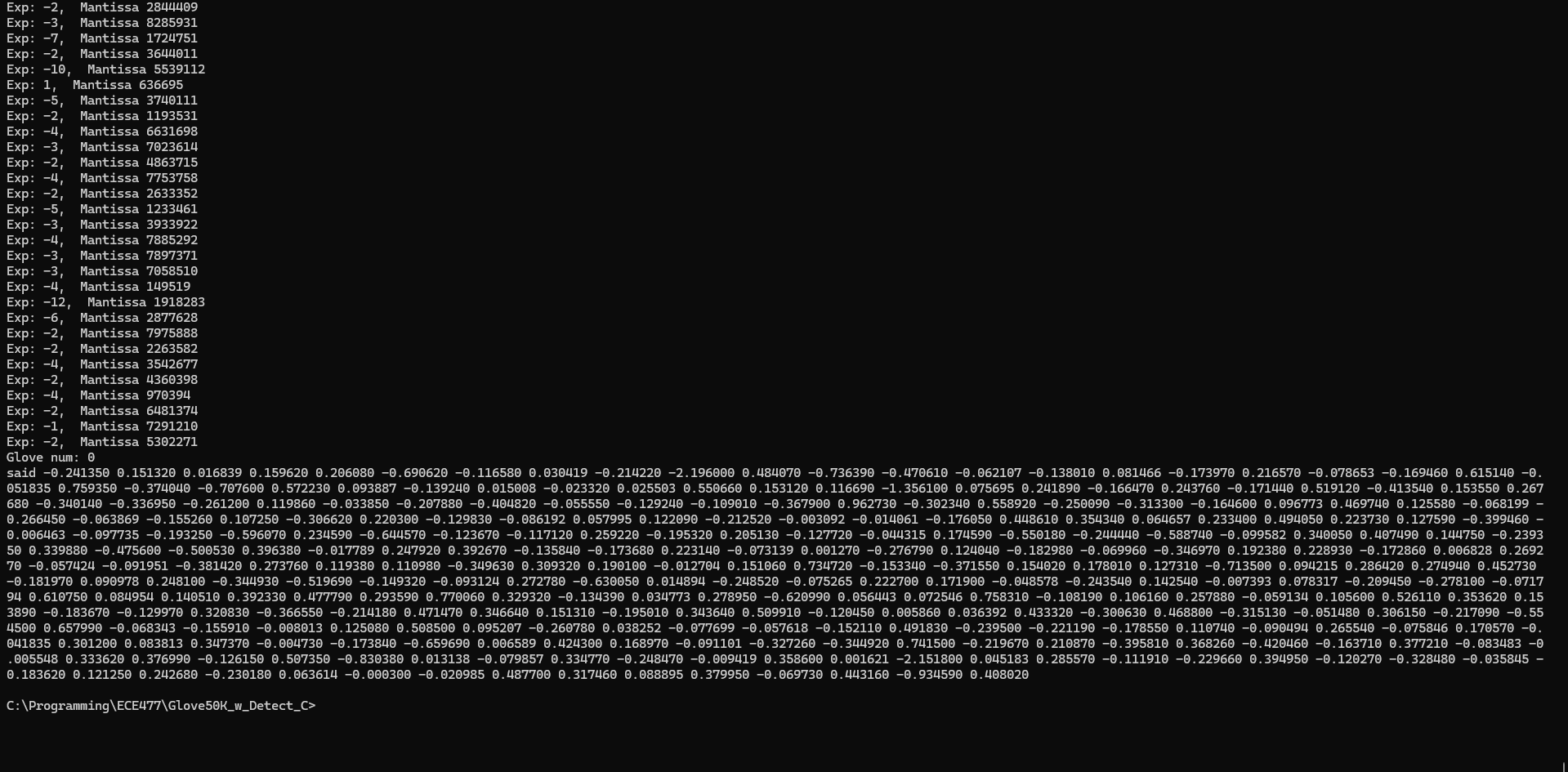
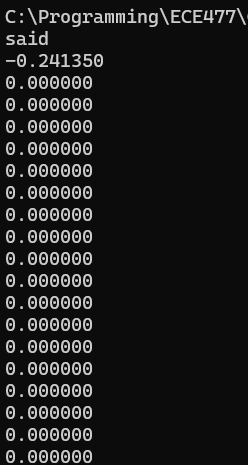
Using IEEE’s Float Conversion Protocol, I was able to properly ready everything in:
https://www.h-schmidt.net/FloatConverter/IEEE754.html
Now, let’s keep going. In the future, however, I’m going to need a different method than this that takes up less storage space. Should be doable via file writing in c.
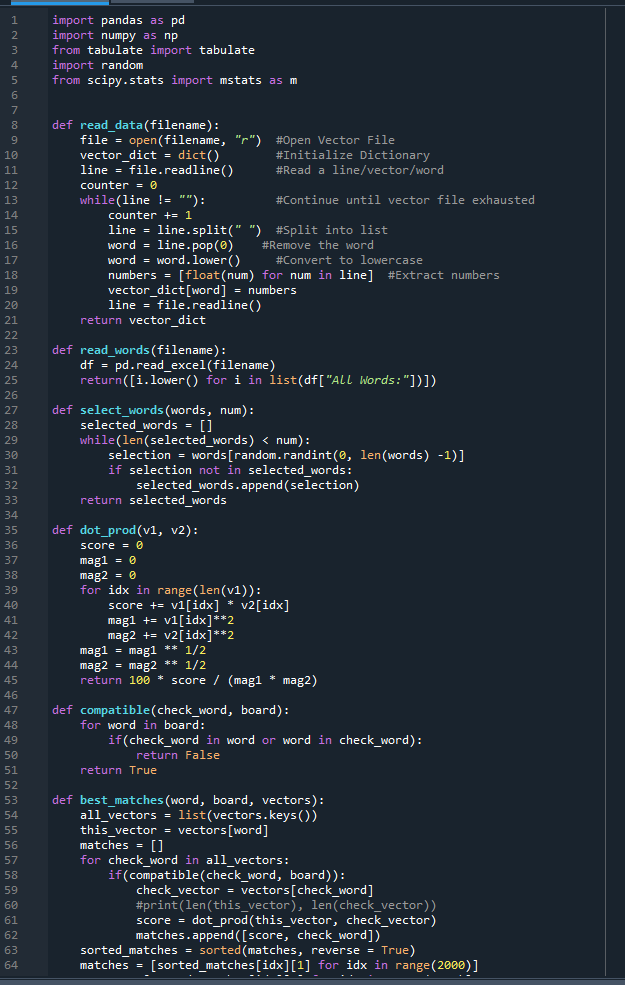
Here, I managed to do something similar for dict to vect:
Now, I’ll try and do the same thing for the document frequencies – maybe computing the score first. I elected to do it with only integers (frequencies):
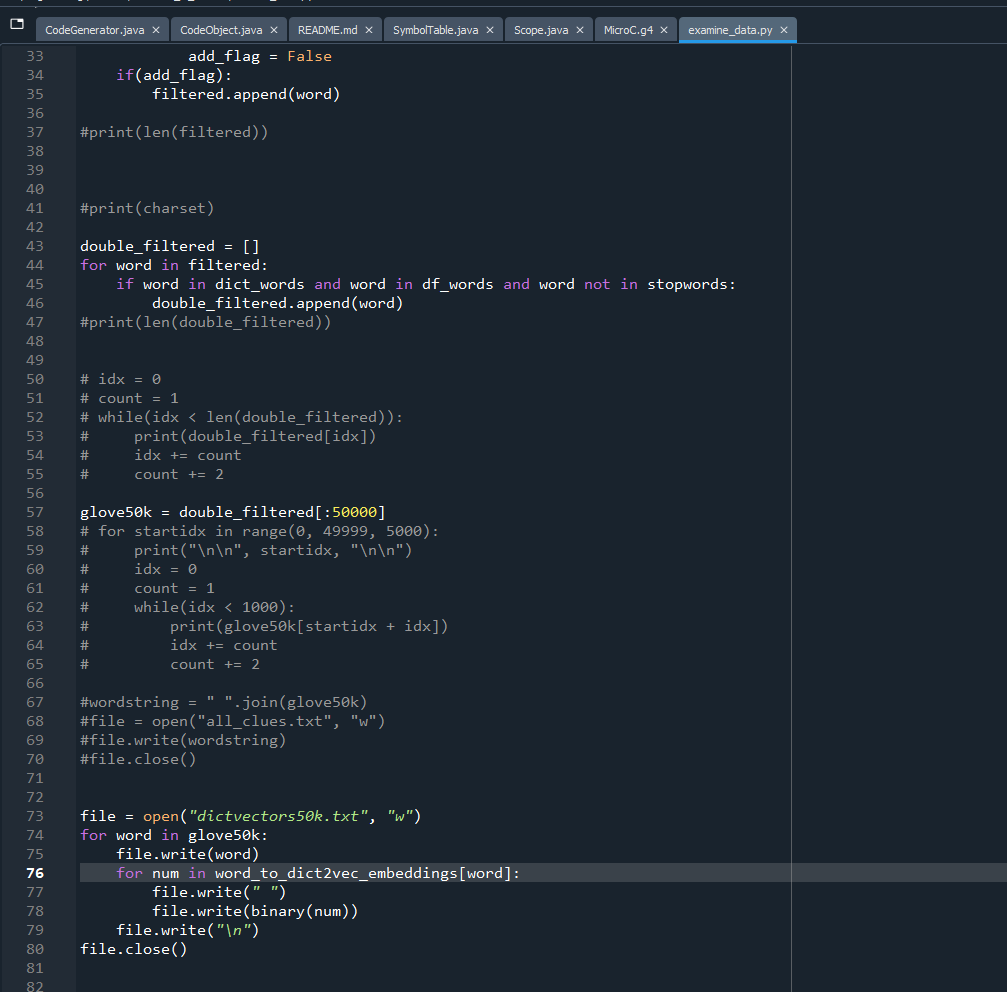
Finished reading everything in, which is a good place to be. This took about 30s runtime (would be more on micro, but its not time critical and I can make it much more efficient):
This also involved collecting a list of all clues.
To do in future: Keep going, get the prototype running now that I have all the input data.
Entry 2:
Date: 10/1/24
Time: 7:30 PM
Duration: 1 Hour 15 mins
Continued to work on just reading the data. Managed to get an output file:
This required decent time processing, and reading the data in Python and messing around with different way of displaying it:
Still don’t know the best way to get the data. Might have to just find some readable form for C, and then do the manipulations in C in order to write a smaller file. In future, will also have to do this for Dict2Vec and DocFreq.
Entry 1:
Date: 10/1/24
Time: 2:30 PM
Duration: 1 Hour 15 Mins
Spoke with Colby about the project progress and my missing time in October.
Getting started on C. Found this for Glove Vectors with C:
https://github.com/shubham0204/glove.c
Looking at how Python is loading Glove Vectors to replicate in C:
https://tedboy.github.io/nlps/_modules/gensim/models/word2vec.html#Word2Vec.load_word2vec_format
Got started, but so used to running on eceprog that I had to go through https://code.visualstudio.com/docs/cpp/config-mingw to install gcc locally.
Eventually got it running, able to look into glove file:
But formatting seems wrong.
To do in future: Figure out how to read the vectors in C
____________________________________________________________________________
Week 6:
Total: 8 Hours 15 minutes
Cumulative: 8.25 + 34.5 = 42.75
Show me a thing: Showed my current Python prototype
Entry 4:
Date: 9/25/24
Time: 1:30 PM - 2:40; 3:00
Duration: 2 Hours
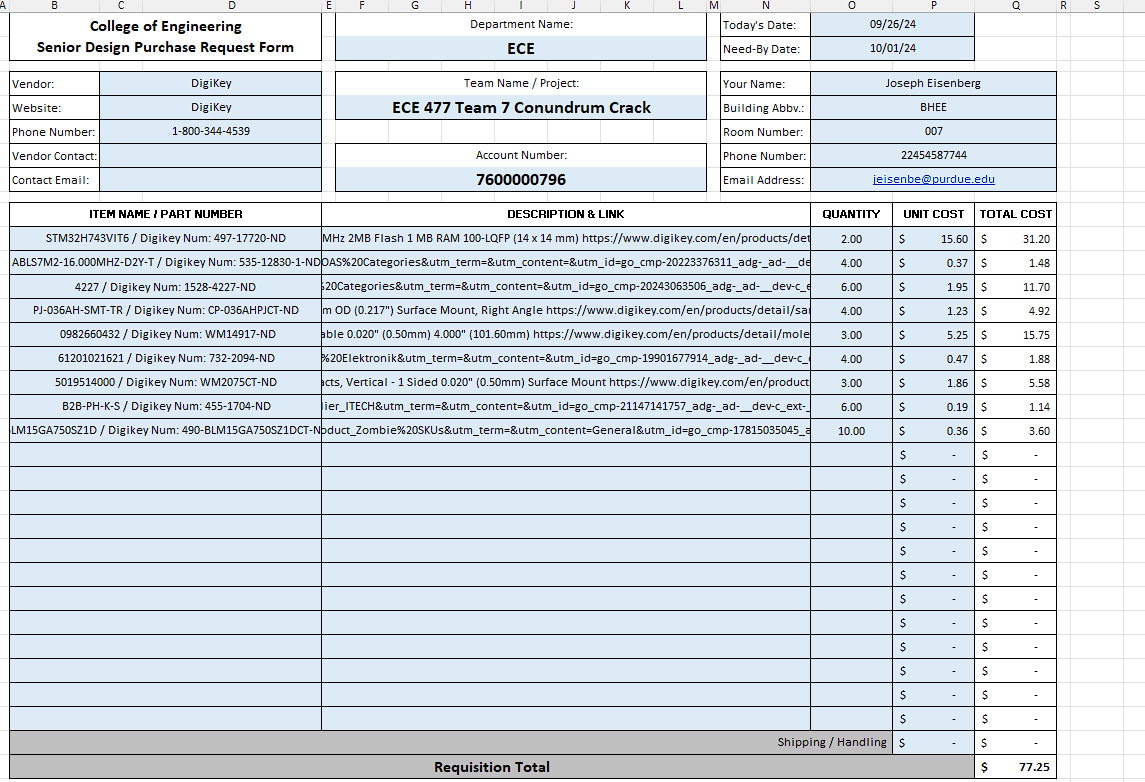
Worked on part order forms for digikey and the display:
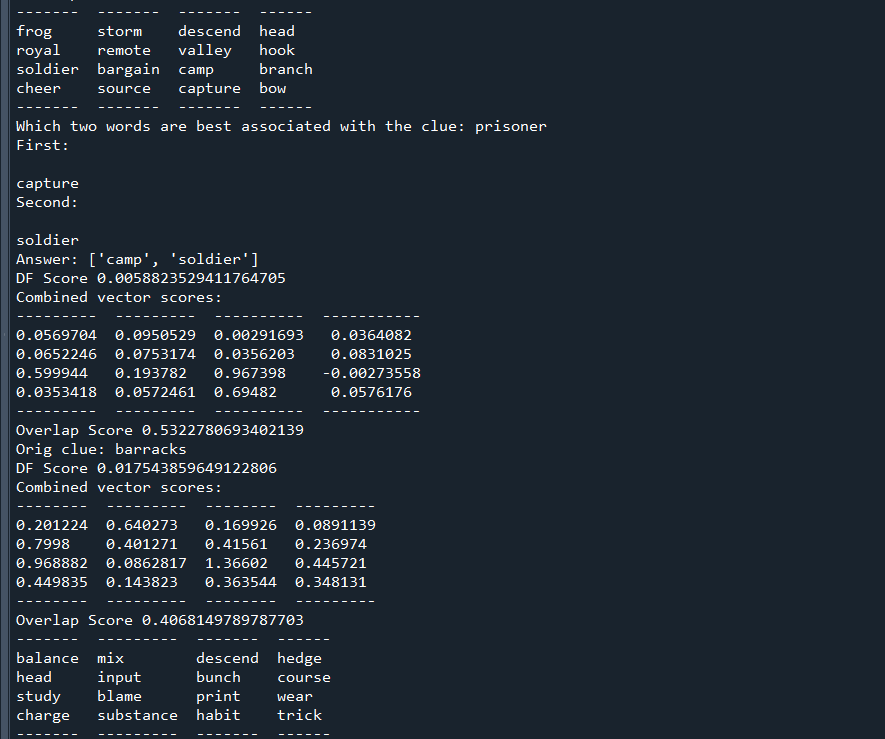
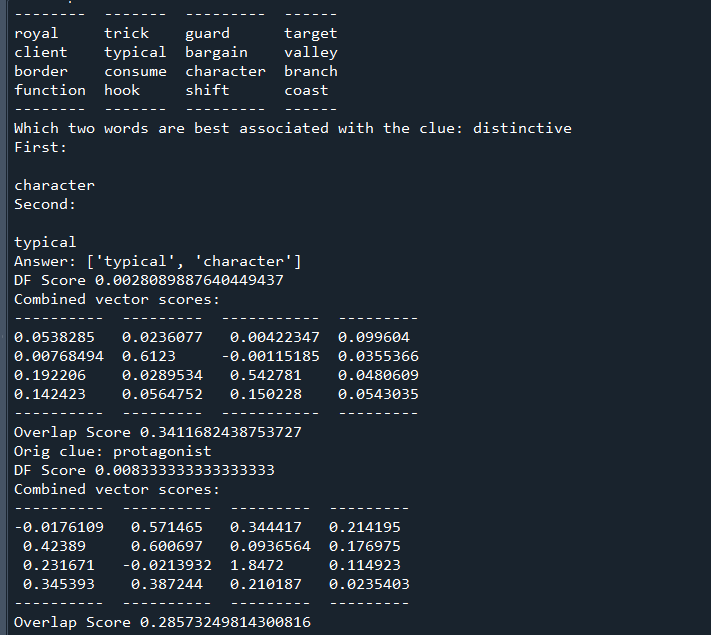
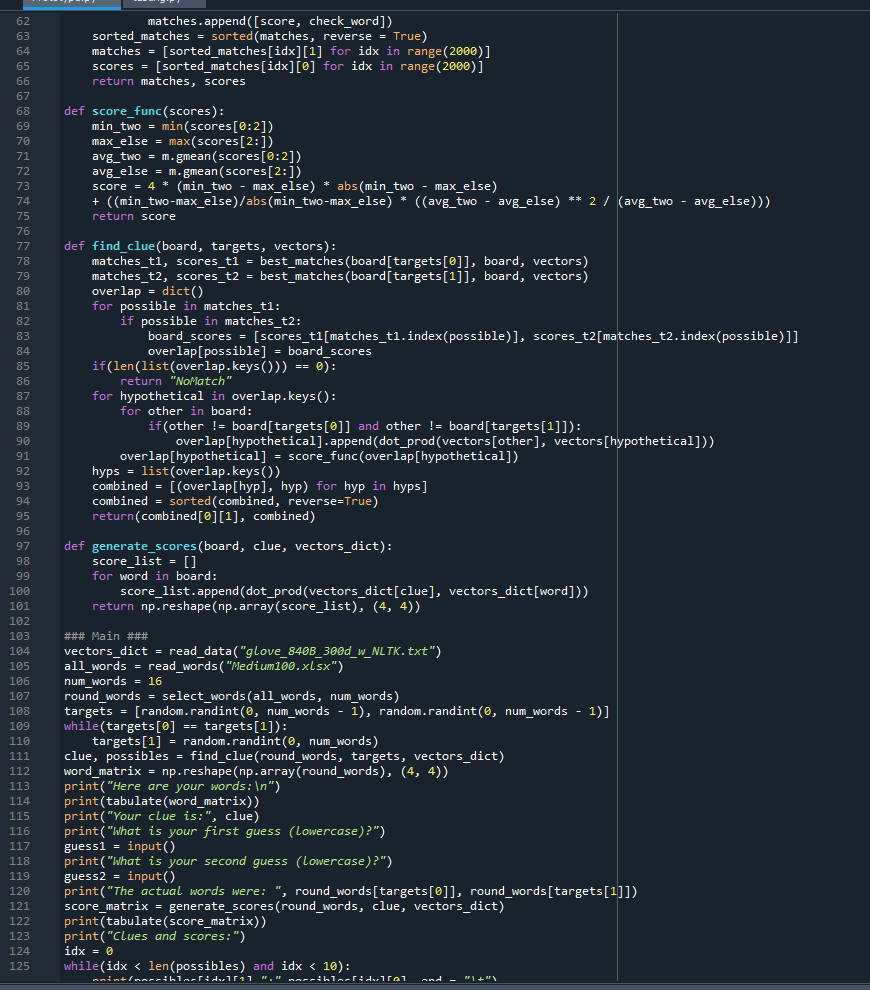
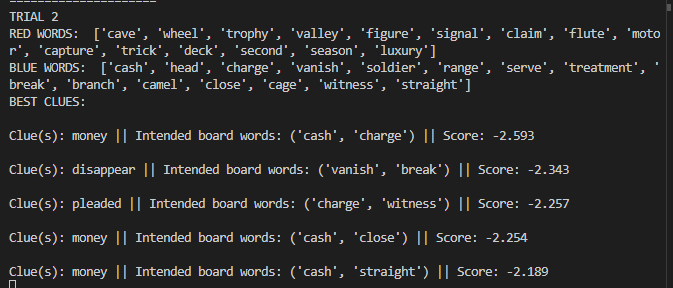
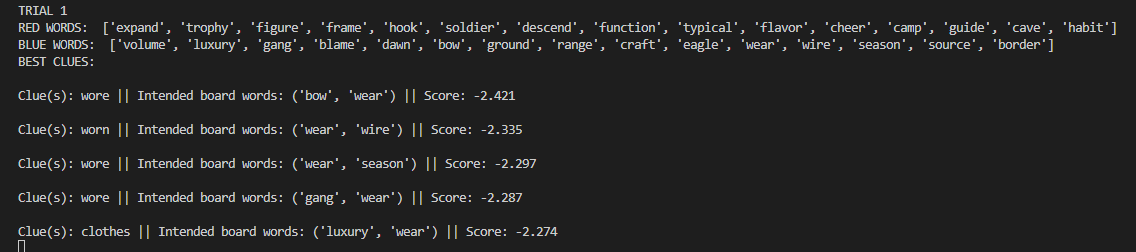
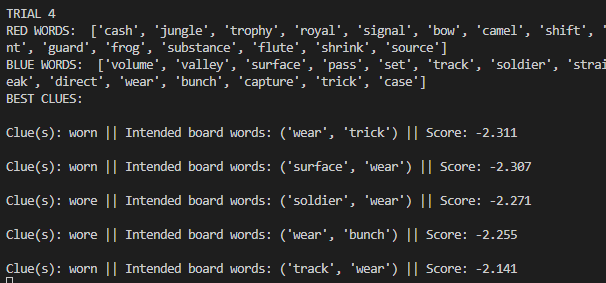
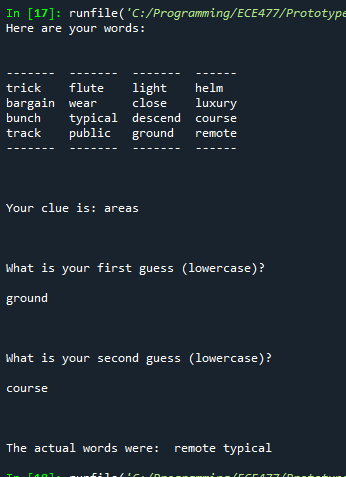
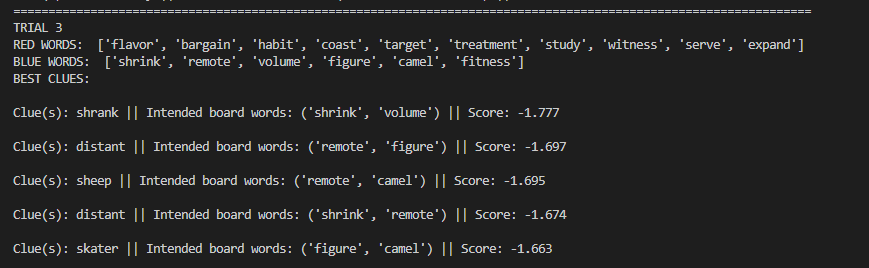
Worked on fine tuning the algorithm. Two changes I thought of: Squaring the two components of vector score to prefer a good score in one over a mediocre score in both; extra-weighting the lesser target vector score (to prefer two medium target scores over one high and one low). Engaged in significant testing to compare the results:
Testing:
My Method produces worse clue:
My method produces better clue:
Oftentimes the same clue is produced.
Interesting case:
Does well if you know (or, like me, look up) that gwr stands for Great Western Railway, a British rail company. Does poorly if you don’t. That’s why it has a high DF score and would be penalized for it, but the strong associations with motor and royal (and poor with everything else) outweigh the DF score. As you can see with the original method’s clue, it is quite hard to capture “motor” and “royal” together – perhaps something like “lamborghini” works, but good luck getting the machine learning algorithm to recognize people associate lamborghini with royalty through wealth/luxury, even though the two words rarely appear together (and lamborghini might not even be in Glove50K).
To do in future: Reimplement in C.
Entry 3:
Date: 9/25/24
Time: 12:30 PM (MANLAB)
Duration: 2 Hours
Discussed ordering parts with teammates and showed work on prototype. Worked on ordering form for items.
Entry 2:
Date: 9/24/24
Time: 9:48 PM
Duration: 4 Hours 30 minutes
Continued programming. First needed to isolate 50k words in glove
(Also tested the various word sources):
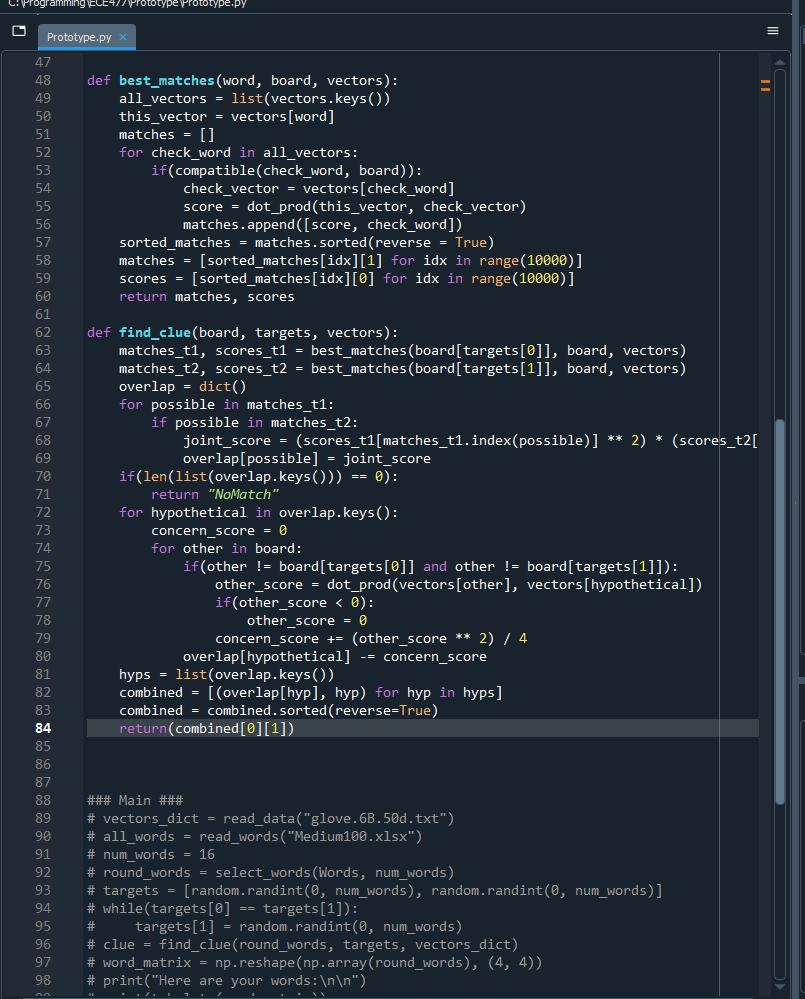
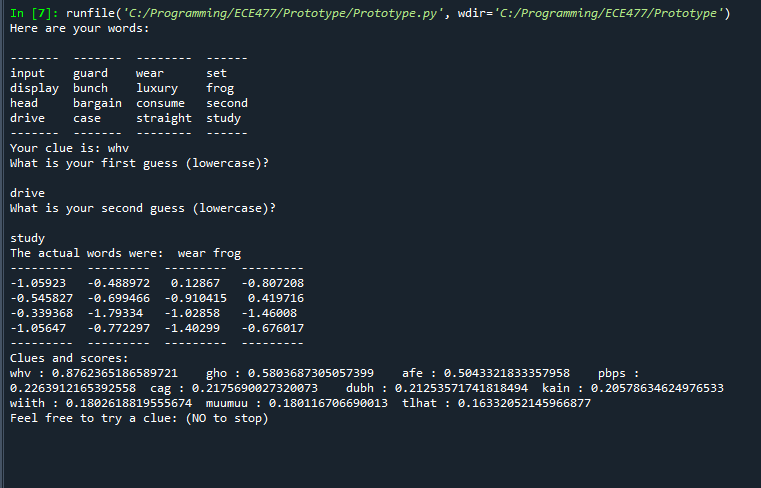
Then, I revisited the prototype and got in to testable form:
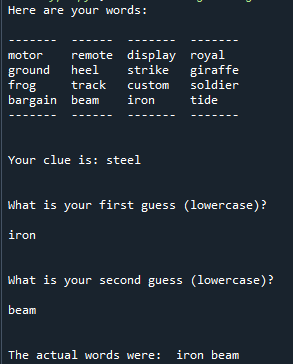
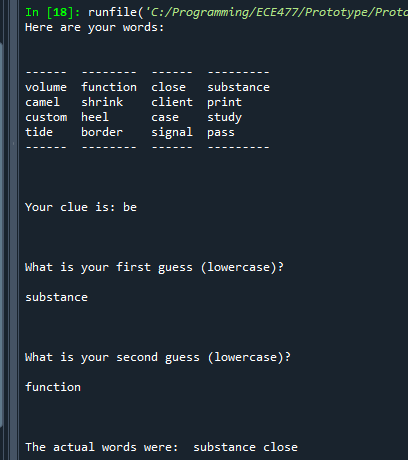
Upon testing I’m not sure how good it is and if everything is going correctly. But it is producing clues related to targets, although the targets seem too easy when connected like this.
To do in future: Refine Prototype
Entry 1:
Date: 9/24/24
Time: 2:30 PM
Duration: 1 Hour 45 Minutes
Discussed Firmware progress with Colby
Discussed possibility of everything at 3.3V and one-sided PCB with Colby
Discussed software plans with Colby for A8. Described plans as outlined in the Journal and sent him relevant links.
Examination of 3.3V wall plugs: https://www.digikey.com/en/products/filter/ac-dc-desktop-wall-adapters/130
Discussed key progress with Andrew
Got started on the serious Python Prototype. Plans:
Code:
To do in future: Keep going on code
____________________________________________________________________________
Week 5:
Total: 8 Hours
Cumulative: 8 + 26.5 = 34.5
Show me a thing: Would have shown my printed copy of the article that most frequents this journal with markings.
Entry 8:
Date: 9/20/24
Time: 4:00 PM
Duration: 1 Hour 30 Mins
Discussed PCB design with Andrew on discord call. Considering one sided, approx 100 mm by 150 mm, with display ⅔ way through the long side. Got started at looking at order form and practices, discussed display ordering choices with Colby in discord, deferring to later. Did produce order form for micro controller, not sending out until more is finalized because we will also be buying other things from Digikey.
Updating website.
To Do in Future: Implementation of paper
Entry 7:
Date: 9/20/24
Time: 1:50 PM
Duration: 30 Mins
More testing and modifying parameters:
Animals give weird clues sometimes, or seem to be attractive matches for some reason. It seems if there is one Animal, and one word on the board related to another animal, it will use that “another animal” to match to both.
Should consider: do we want animal board words? Geographic ones still under consideration too.
Tried testing with a huge set of words for each team to help get an idea of what words tend to “stick out” and frequently appear in clues.
Concern: if one word is strongly related to a board word, it will strongly bias that as the clue word:
Sometimes perhaps these words have to be removed as options for targets, but sometimes I don’t know how much there is to do about it. One metric is “minimum association score to a target word”, but I want to consider both scores. Maybe Sum of both + minimum?
And again:
Perhaps changing algorithm so everything but the two target words is a “red word” will help.
Not bad with disappear, flavor/flavour a concern.
To do in future: Implementation (I didn’t wanted to get started until I had a decent block of time).
Is there a way to implement avoidance of tense problems?
Entry 6:
Date: 9/20/24
Time: 10:53 AM
Duration: 30 Mins
Research into word difficulty classification:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10661753/
Seems ok but for non native speakers. Don’t know if there’s a difference there, and maybe that’s even better. Also, unsure if this data set is extensive enough.
Doc Freq does help serve as a difficulty measure and is in DETECT. Might be decent for clue difficulty level, but uncertain about board words. Those might be more manual, anyways.
API that will do this:
https://www.twinword.com/blog/how-to-check-english-word-difficulty/
One concern: doc freq might make different forms of the same word have different difficulties. Consider:
Hike
Hiker
Hiking
Hikes
Hiked
To do in future: work on implementation
Entry 5:
Date: 9/19/24
Time: 10:53 PM
Duration: 1 hour 45 mins
Reading Dict2Vec paper. Want to see if there’s a more recent option.
Looked at the github, hasn’t been updated in years. Also, found this relevant article; https://www.cambridge.org/core/journals/apsipa-transactions-on-signal-and-information-processing/article/evaluating-word-embedding-models-methods-and-experimental-results/EDF43F837150B94E71DBB36B28B85E79
Worked on this week’s assignments also.
Scanned through “cited by” on Dict 2 vec to see if there’s anything useful.
Not much useful, although there are relevant articles there.
Read through Dict 2 Vec. High detail not needed, but some notably points:
Out of a desire to see if there’s much else out there more recently, I looked at this:
https://link.springer.com/article/10.1007/s11042-023-17007-z
Upon examination, that article was unsatisfying, so I opted instead for this:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10100347
It was written in 2023, and, being as contextualized word embeddings (a word has different vector values in different situations) aren’t relevant to our work, and that it still mentions the commonly discussed GloVe, fasttext, and Word2Vec, it doesn’t seem to have much to add.
To do in future: Look at word classification by difficulty, work on implementation
Entry 4:
Date: 9/19/24
Time: 5:20 PM
Duration: 30 minutes
Discussed my findings from the article, planned PCB design, PCB size, PCB location of different parts, etc. with Colby and Andrew. Thinking PCB will end up decent size (6 x 8 in ish), that will have to be careful with high freq SPI signal to display but should be ok with short ribbon cable.
To do in future: same as below
Entry 3:
Date: 9/19/24
Time: 1:40 PM
Duration: 2 Hours 15 mins
Continued reading article:
As a result, here’s the approach I’m thinking of using:
Something like this might be a best first implementation.
Useful to further examine Dict2Vec: chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://aclanthology.org/D17-1024.pdf
Now, need to update the website in accordance with yesterday’s input from Prof. Walter.
Added info on LDO, low-fidelity audio at base, stretch audio software goal, etc.
Now I need to look over A7.
Seems like we still need:
Speaker
Amplifier
SD Card Reader
Power Port
Key switches
LDO
DC Wall Adapter?
Added these to the document and will discuss with group in future.
Also to do: implementation of GloVe + DETECT. Further reading on Dict2Vec.
Entry 2:
Date: 9/18/24
Time: 12:30 PM (MANLAB)
Duration: 2 hours
ECN granted a request to increase my storage limit to 25 GB. Was able to run their code using their formatting, even with Babel net (got a key):
Meeting: need specific voltage, LDO, amplifier on stretch goal, low fidelity audio feedback in main descrip, stretch software audio generation.
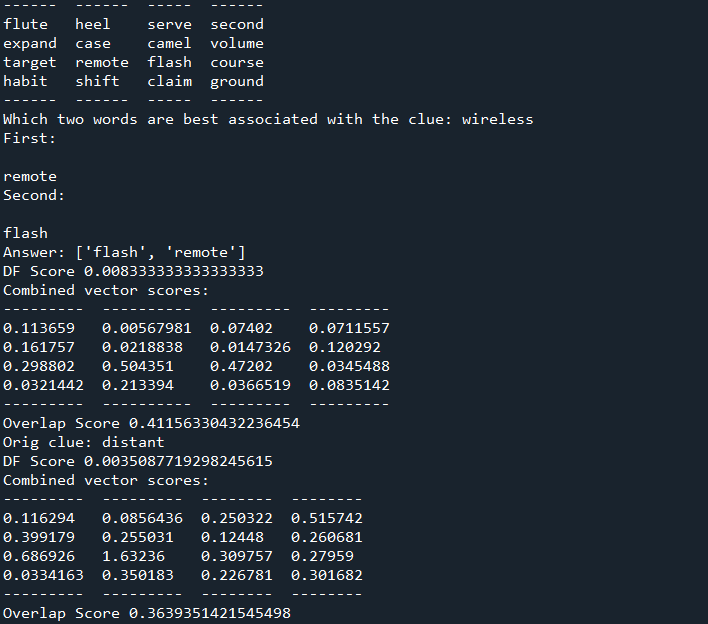
Now, I’ll try and configure it with my words. I put my 100 words in a text file and have the Python code read it. Doesn’t work with Babel because I’d need to generate data files for every word. Can do that later. Does work with glove. Clues aren’t perfect though:
Also seeing how important it is to select the right board words (flavor causes issues):
Clues aren’t bad, probably need to allow more than 2 words as possible for clue selection:
To do in future: Continue implementation, finish article
Entry 1:
Date: 9/17/24
Time: 2:10 PM
Duration: 1 Hour
Discussed Display and the visual design with Colby, as well as the article I've been making my way through. Also discussed materials, this week’s assignment.
Started trying to set up the article’s codenames program. I first tried locally, and had difficulties with the pip installs, so I cloned to ECEPROG, which seems to work better. Installing took a while but the Github linked below has already
Update: Tried download all needed data on ECEPROG, didn’t have enough space, requesting more. Will probably just have to keep going on reading article until then.
To do in future: finish article, continue implementing
____________________________________________________________________________
Week 4:
Total Hours: 8
Cumulative Hours: 18.5 + 8 = 26.5
Show me a thing: I showed the SpaCy vectors in ManLab. Didn’t get to show too much detail, but would have discussed how I’m collecting them in Python from SpaCy module, and how I can use them in place of GloVe vectors in prototype code. Would also have shown how the spacy results are questionable in comparison to the GloVe results, and that I was considering just abandoning SpaCy vectors from consideration.
Entry 6:
Date: 9/13/24
Time: 4:35 PM
Duration: 45 Mins
Looked over, edited A5 (wrote several paragraphs for the display sections, project website (
Continued reading:
Updated website
To do in future: continue reading / explore code
Entry 5:
Date: 9/13/24
Time: 12:40 AM / 9:30 AM / 1:30 PM
Duration: 2 Hours (Continued right where I left off without an easy break point for these entries in the morning and then in afternoon)
Looking at further results, it seems like SpaCy vectors are simply inferior to the GloVe vectors, and so I will likely remove them from consideration as I continue reading through the paper in entry 5 of this week.
Continued reading paper, results:
To do in future: continue reading, start exploration of their code
Entry 5:
Date: 9/12/24
Time: 1:34 PM
Duration: 2 hours 30 minutes
Working on evaluating SpaCy vectors. My test will be finding the 100 most similar words for every word that could be on the board. If I like the results, maybe I will keep going with them. If not, will eliminate SpacY vectors from consideration.
Order of words to keep track of later:
close
second
cash
descend
consume
bunch
input
expand
character
fitness
cage
camel
eagle
giraffe
frog
display
flute
craft
bruise
helm
blame
cheer
capture
claim
case
branch
flavor
bench
frame
hook
balance
cave
coast
hedge
ground
gang
course
drive
charge
deck
camp
client
guard
border
beam
bargain
bow
break
edge
figure
function
guide
public
set
heel
treatment
target
track
trophy
flash
signal
wire
custom
motor
pass
direct
head
serve
shift
strike
volume
habit
valley
storm
jungle
tide
iron
dawn
trick
typical
wear
witness
vanish
wheel
soldier
strain
luxury
straight
royal
remote
shrink
mix
substance
study
light
surface
source
season
Range
better than I thought so far:
Although the bottom half – not so great. We’ll see.
Maybe calculating similarity wrong
Discussed component choices with Colby (leaning to 100pin h7 for processing power, 9” screen for price / usability).
Looking at options for Spacy vector similarity: https://towardsdatascience.com/how-to-build-a-fast-most-similar-words-method-in-spacy-32ed104fe498
Reading Article: https://www.jair.org/index.php/jair/article/view/12665/26691
Notes from article:
To do in future: Keep reading article
Entry 4:
Date: 9/11/24
Time: 12:30 PM (MANLAB)
Duration: 2 Hours
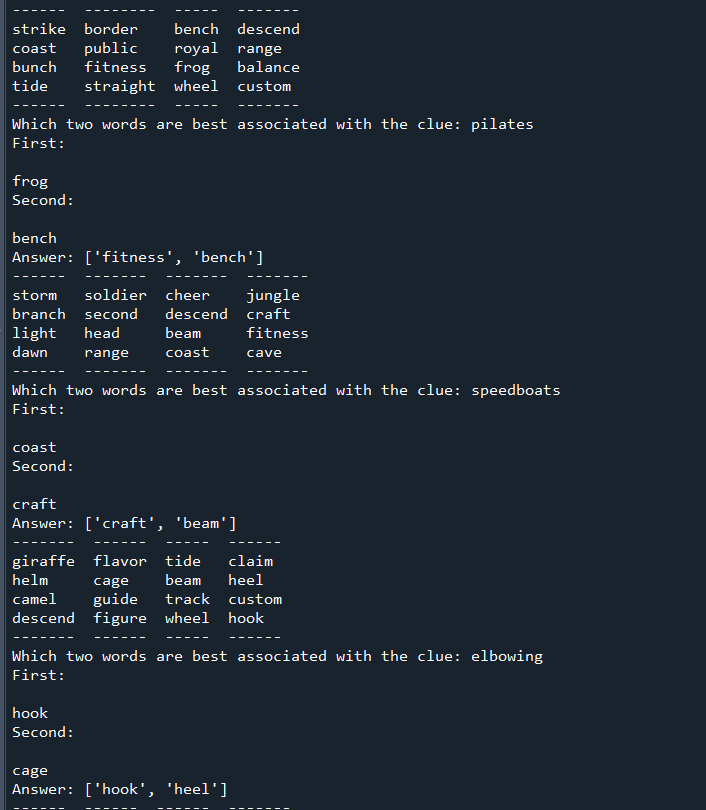
Trying to see what I have to work with for clues. Not pleased:
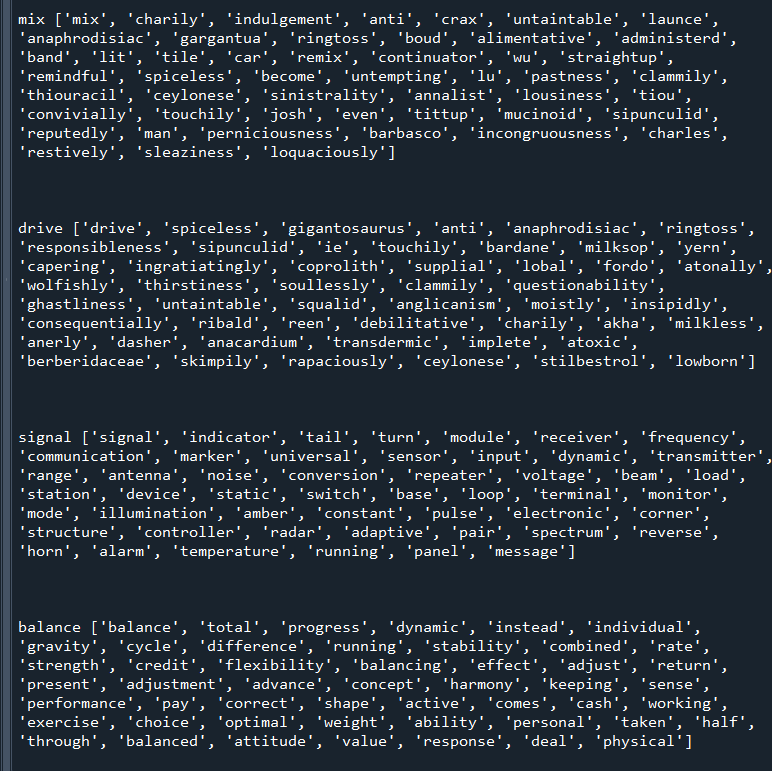
Top 50 associations with some words from SpaCy.
And from GloVe:
Better (especially signal), but not great (see charily for mix, spiceless for driver, and instead for balance in top 5.
Makes me think I’m at least calculating scores right for Glove, uncertain about SpaCy. Want to work on figuring out a way to get a more concrete improvement – finding a half-decent clue for two words should be that bad.
Might be time to also research other methods than GloVe vectors, and see if there is even a good way to get a reliable clue allowing picking/choosing of which words to provide a clue for.
Looked for some possible displays and chips:
Discussion with Colby:
1000 board words by 200K clue words should fit on SD Card
Add Power to description, more detail in general
Entry 3:
Date: 9/10/24
Time: 3:50 PM
Duration: 30 minutes
Showed SpaCy results to Aloysius and Colby. Intersected it with NLTK to try a reduced number of words. Seems that my method of grabbing takes in less words than expected, examine in future.
55K Words after intersecting with NLTK.
To do in future: Test why I’m getting less words than I expect
Entry 2:
Date: 9/9/24
Time: 12:40 PM
Duration: 30 minutes
Some testing with Andrew in lab. Examples of shortcomings:
Also discussed current issues with the display and microcontroller testing with Andrew. It also simply takes too long because of large numbers of words.
To do in future:
Improve SpaCy vectors implementation, explore how it works more.
Entry 1:
Date: 9/8/24
Time: 4:35 PM
Duration: 2 Hours
Time to take a look at SpaCy vectors.
https://spacy.io/usage/spacy-101#vectors-similarity
54197 words in Spacy and nltk.lower()
661749 words in Spacy
114720 other things in Spacy
Took a while, but processed all of Spacy words ([a-zA-Z] chars).
Then processed again because many words didn’t actually have vectors.
Now, down to 441k words.
Got it working, not particularly impressed by it yet either:
To do in future: Better understand SpaCy vectors and their usage. Maybe try their similarity method. Better clues should hopefully be possible.
____________________________________________________________________________
Week 3:
Total Hours: 8
Cumulative Hours: 10.5 + 8 = 18.5
Show Me a Thing: Showed my current prototype
Entry 7:
Date: 9/6/24
Time: 4:10 PM
Duration: 45 minutes
Finished and turned in A3, updated website.
Entry 6:
Date: 9/6/24
Time: 12:44 PM
Duration: 1 hours 30 minutes
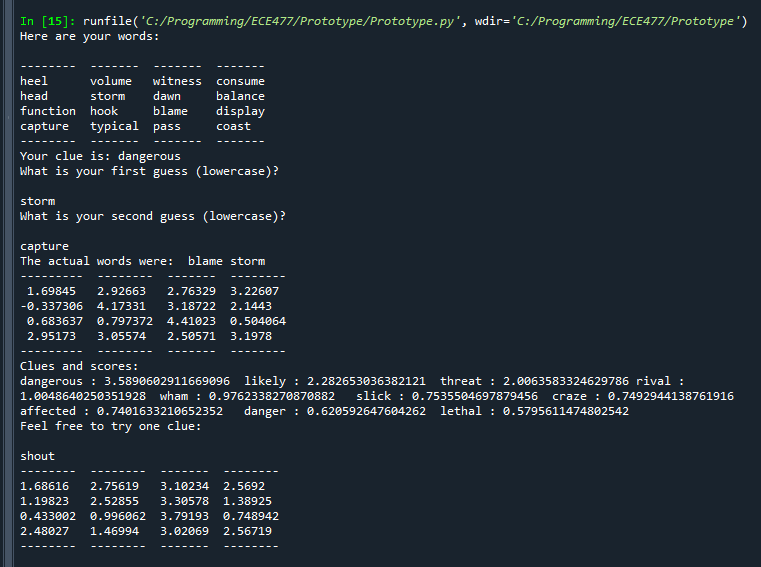
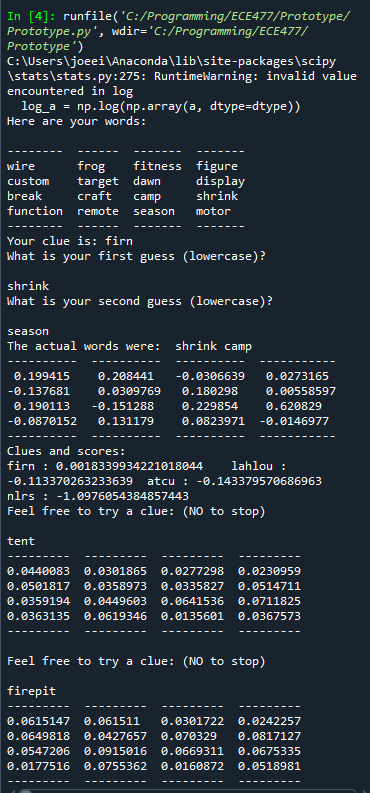
Started by fine-tuning code generation. Result appears to be that a good clue is selected based on the scores, but the scores don’t do a good job of capturing effectiveness of a clue. For example:
Here, based on the scores, dangerous looks decent – very high associations with blame and storm. But with words like witness and capture out there, its a confusing clue – not good at isolating our words. When I tried to come up with a clue – shout (as in, shout in anger for one’s blame, and shout up a storm), it had good association with blame, but middling with storm.
Here, for example, we see the computer can’t come up with any good clue, so it comes up with what is arguably decent. I would have thought something like escape or storm would work better:
Sometimes, a word that would have been good isn’t even in the list of words, leading to an unusual and poor clue:
Overall, the current vectors method does not inspire confidence:
Here’s the current state of all the code:
And the code to generate the dataset:
“glove.840B.300d.txt” comes from Stanford.
Here is a summary of viable methods of improving the program:
I don’t know which is best, but I’m probably going to have to try something. 1 and 2 seem easier to try (to do in future), 3 and 4 seem more painful.
Worked on A3:
To do in future: Finish A3, update website
Entry 6: 9/5/24
Time: 6:20 PM
Duration: 15 mins
Testing prototype, adjusting selection parameters.
To do in future: A3, Website, improve prototype clue
Entry 5:
Date: 9/5/24
Time: 1:44 PM
Duration: 2 hours 30 minutes
Working on A3
https://www.st.com/resource/en/product_training/stm32l4_peripheral_sdmmc.pdf
SDMMC
PWM: https://controllerstech.com/pwm-in-stm32/
Worked on Flowcharts:
Also discussed clue issues with Colby (Example: Grenade for Soldier, Palm, Round in jsomers link), discussed network-based approach (node for each word, link for a strong connection, find the closest distance between two words for a clue).
Also added a way to see alternative clue options, and test them.
Worked on researching ways to overcome the deficiency of vectors;
https://futurumcareers.com/teaching-computers-to-understand-our-language
On data for training: https://www.reddit.com/r/boardgames/comments/12phddz/codenames_gameplay_dataset/
More research:
https://github.com/allenai/codenames/tree/master
https://paperswithcode.com/dataset/winogavil
https://arxiv.org/pdf/2210.09263v1
Someone else who tried this with glove vectors:
https://www.psychologytoday.com/us/blog/psyched/202204/what-i-learned-creating-ai-play-codenames
Code: https://github.com/SilverJacket/Codenames
Word Vectors: https://dzone.com/articles/introduction-to-word-vectors
SpaCy for vectors: https://spacy.io/api/vectors
https://www.geeksforgeeks.org/python-word-similarity-using-spacy/
Added lowercase words in nltk to document, up to 85K words for possible clues.
Modified score to heavily consider min-maxing: (first two scores are the clue words)
Entry 4:
Date: 9/4/24
Time: 12:30 PM (MANLAB)
Duration: 2 Hours
Showed progress of prototype code to teammates, tested it.
Looked over A3 – my assignment.
Looked at glove vectors background for improvement ideas: https://jsomers.net/glove-codenames/
Ideas from reading it over:
Need more detail in functional description, revise PSDRS.
Modified prototype to use Cosine SImilarity (divide out magnitudes). Messing around with selection parameters.
To do in future: A3, minmax optimizing?
Entry 3:
Date: 9/4/24
Time: 10:45 AM
Duration: 15 minutes
Replaced backpack with expand in “board words” excel file. Modified selection parameters further.
To do in future: Show program as “show me a thing” in lab today, discuss with teammates a direction to move forward on clue selection, continue optimization.
Entry 2:
Date: 9/4/24
Time: 1:40 AM
Duration: 30 minutes
Upgraded to using intersection of NLTK with 840B token Glove vectors, 75k words. Worked on revising selection parameters to limited success.
Some updated code:
To do in future: fix error with preselected word backpack (not in NLTK), revise selection parameters
Entry 1:
Date: 9/3/24
Time: 2:02 PM
Duration: 2 Hours,15 minutes
First goal: get list of all relevant english words.
https://stackoverflow.com/questions/772922/free-word-list-for-use-programmatically
Tried NLTK: 236K words, too many
Tried it out – first 5 files contained only 2300 words. Not nearly enough.
More searching:
https://stackoverflow.com/questions/56512661/list-of-regular-english-words
https://www.mit.edu/~ecprice/wordlist.100000
https://github.com/first20hours/google-10000-english
https://en.wiktionary.org/wiki/Wiktionary:Frequency_lists/English/Wikipedia_(2016)
https://wortschatz.uni-leipzig.de/en/download/English
Leipzig download doesn’t seem useful:
https://github.com/arstgit/high-frequency-vocabulary/blob/master/30k.txt
Ended up intersecting NLTK with the 300D glove_6B wordset, gave me 51K words. In future, might do same for 840B Glove dataset. Runs faster now, significantly. Writing my own dataset from the intersection has helped me remove some formatting errors.
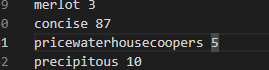
Got program to print out scores for a round. Will use to correct clue selection algorithm:
To do in future: work on clue-selection algorithm, explore 840B glove dataset
____________________________________________________________________________
Week 2:
Total out of lab hours: 8
Cumulative out of lab hours: 2.5 + 8 = 10.5
Entry 6:
Date: 8/30/24
Time: 12:35 PM
Duration: 2 hours
Tested the program with Andrew. Fixed a bug where it would randomly select an index out of range for one of the target words.
Testing revealed the clues need some work. Occasionally, on the less detailed Glove vector files, it would give a clue that wasn’t a real word. With the more detailed one, it has at least been using a word, but with questionable clues. Also, the program runs slow.
Worked on the website. Posted PSDRs using feedback from our TA.
Looked over and made edits to A2 – the functional specification.
Troubleshooting how to add these documents to the website.
To do in future:
Entry 5:
Date: 8/30/24
Time: 10:18 AM
Duration: 1 Hour
Worked on figuring out how to add a report to the website.
Found out all past work on the website was accidentally removed.
Read some of https://jaycarlson.net/microcontrollers/ to get an idea of the environment out there.
Updated the team page with team member information.
To do in future: Add everything back to the website
Entry 4:
Date: 8/29/24
Time: 8:21 PM
Duration: 2 Hours
Continuing work on code.
Got it partially function, run examples:
Because of poor clues, I tried using a larger data file (300 dimensions instead of 50). That helped significantly:
After substantive testing, the clues aren’t terrible but also aren’t very good. Maybe more training would help (larger dataset). Is there a way to reformat this nicely – that would help A LOT
To do in future: Fix a few of the bugs I patched with bandaids (sometimes, doesn’t read input file correctly, sometimes calling best_matches has an error for list index. Improve clue quality – don’t know how, though.
Best clue so far:
Here’s the current code:
Entry 4:
Date: 8/29/24
Time: 2:07 PM
Duration: 2 Hrs 15 mins
Working on a prototype version of clue-giving.
GLoVe Vectors found here: https://nlp.stanford.edu/projects/glove/
Need to find a vocab set for words that can appear. Will try and create a 100 word version.
Finding words here: https://www.englishprofile.org/american-english
Limiting to B1 and B2 (Intermediate)
Self selecting based on perceived appropriateness for game
Now, Prototype in Python.
Revised to 6B token Glove Vectors for size concerns. Still have larger version.
Code:
To do in future: Finish Python version
Entry 3:
Date: 8/28/24
Time: 12:30 PM
Duration: 2 Hours (ManLab Hours)
Further research. Team working on Microcontroller and display.
Associations:
https://www.kaggle.com/datasets/anneloes/wordgame
Further Associations Work:
https://github.com/monolithpl/word.associations
Thoughts after looking into word associations:
Worked on A2, discussion on how the game will work and word associations.
Clue Generation for codenames:https://jsomers.net/glove-codenames/
To do in future:
Entry 2:
Date: 8/27/24
Time: 5:20 PM
Duration: 15 Mins
Discussed clue selection with Colby. Ideas include:
To do in future: Pick a method of clue selection
Entry 1:
Date: 8/26/24
Time: 2:10 PM
Duration: 30 Mins
Research/Work on my own regarding program
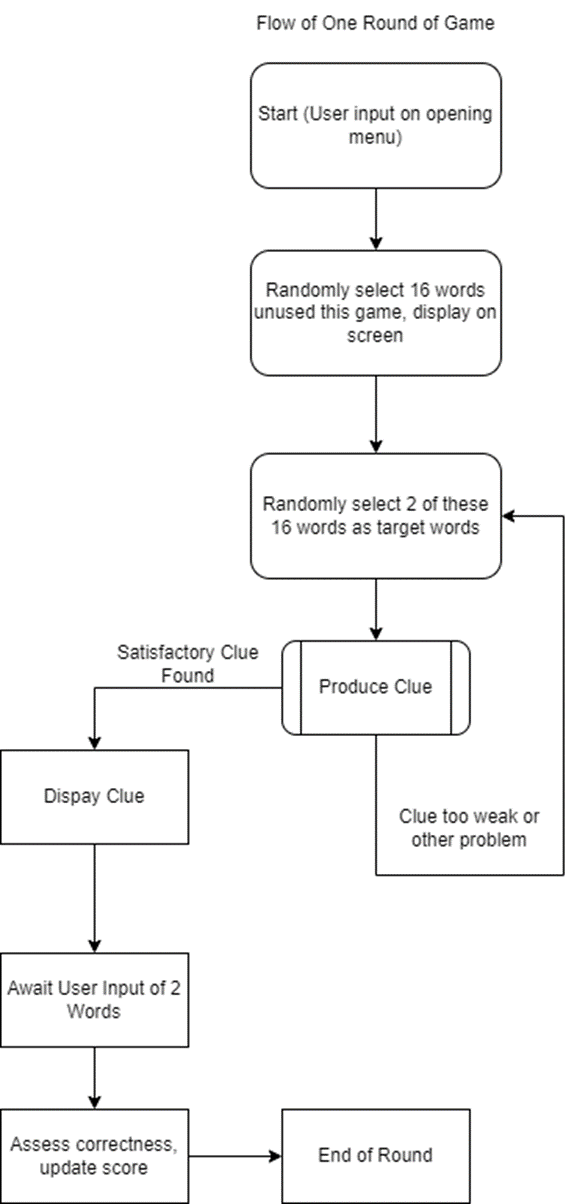
Overall Flow of Each Round:
Flow for Clue Production:
Word Association Dataset: https://aclanthology.org/2022.aacl-main.9/
Other Word Association Dataset: https://smallworldofwords.org/en/project/research
General Text Dataset: https://pile.eleuther.ai/
Other Text Datasets: https://github.com/niderhoff/nlp-datasets
Synonym Lexical Dataset: https://wordnet.princeton.edu/
10 TB of text: https://paperswithcode.com/dataset/massivetext
To do in future: Pick a method of clue selection
____________________________________________________________________________
Week 1:
Total hours outside of lab: 2.5
Cumulative outside of lab hours: 2.5
Explanation: In the first week, due to things getting started and adjusting, full 8-12 hours did not take place.
Entry 3:
Date: 8/22/24
Time: 2:00 PM
Duration: 1 Hour
To do in future:
Entry 2:
Date: 8/21/24
Time: 9:00 PM
Duration: 1 Hour 30 mins
To do in future:
Entry 1:
Date: 8/21/24
Time: 12:30 PM
Duration: 2 Hours (ManLab hours)
To do in future: